(图片来源:摄图网)
近日,中国科学院院士、华科智谷人工智能研究院院长何积丰在瞰见未来2024复旦管院新年论坛上以《人工智能重塑人类未来》为主题发表演讲,并接受了《每日经济新闻》记者采访。
活动现场,何积丰向大家介绍了人工智能的安全隐患客观上会产生的两大威胁。他指出大模型开启了真正意义上的通用人工智能,然而人类是否有能力驾驭这一比人类学习能力更强、更聪明的物种,目前并没有明确的答案,仍在探索之中。其次,大模型的通用能力让其能够应用到人类生产生活的各个场景中,可谓无孔不入。何积丰表示,一旦AI出现安全问题,其影响将难以预估。
何积丰进一步解释,除了在训练过程、使用过程中可能发生数据隐私泄露,生成式大模型依靠语料库,还会按照‘意志’对数据进行修改,而为搜索引擎建立的数据保护策略对大模型也无法奏效。
而关于个体呢?随着AI越来越多地介入职场生活,何积丰指出,目前AI取代人类工作的时间被大幅提前了10年,在2030年至2060年间,50%的职业将逐步被AI取代。好消息是任何新技术都会带动相关岗位增长;坏消息则是部分传统岗位或将逐渐退出历史舞台。 他强调,人类进行技术研发是为了有智能助手来帮助我们提升效率,而并不希望出现教会徒弟,饿死师傅的情况。
那怎样才能避免被淘汰呢?答案很简单——持续学习进步并利用好手中神器。我们需要以专业优势和主观能动性强化自身竞争力,并思考怎样将AI有效集成进工作流程中提升效率。
最后,何积丰在采访中指出,当前的大模型技术仍不具备自主学习的能力,所以我们要想办法走在AI之前,发挥人的主观能动性。
——AI大模型是一种新的智能计算范式
近年来出现的超大规模智能模型,简称大模型,是一种新的人工智能计算范式。与传统AI模型相比,大模型的训练使用了更多的数据,具有更好的泛化性,并且可以应用到更广泛的下游任务中。根据应用场景的不同,AI大模型主要包括语言大模型、视觉大模型和多模态大模型等。在自然语言处理领域,业界典型的自然语言大模型有GPT-3、源、悟道和文心等。视觉大模型也已广泛应用于自动驾驶、智能安防、医学影像等领域。此外,基于多模态大模型的以文生图技术也迅速发展,AI内容生成(AI Generated Content,AIGC)已成为下一个AI发展的重点领域。

——中国AI应用在金融、电信制造、医疗行业加速渗透
当前,随着数字经济与实体经济融合程度的不断加深,以及互联网平台的数字化场景向元宇宙转型,人类对数字内容总量和丰富程度的整体需求不断提高。AIGC作为新型的内容生产方式,已经在传媒、电商、影视、娱乐等数字化程度高、内容需求丰富的行业取得重大创新发展,市场潜力逐渐显现。同时,在推动数字实体结合、加快产业升级的进程中,金融、医疗、制造、工业等各行各业的AIGC应用也在快速发展。
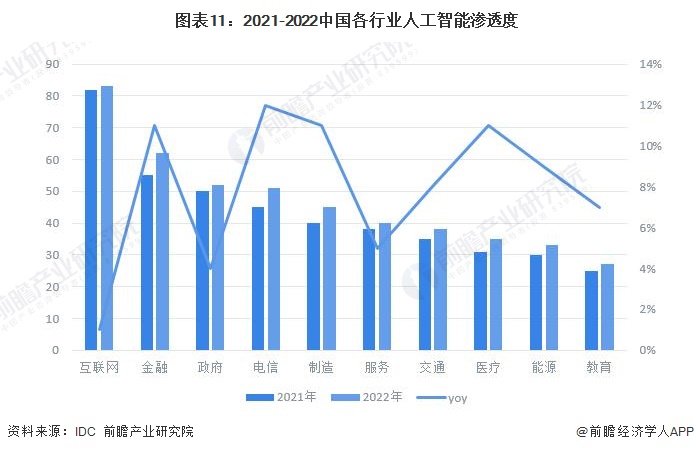
据IDC数据显示,2022年中国人工智能行业应用渗透度排名前五的行业依次为互联网、金融、政府、电信和制造。此外,AI为自动驾驶、交通物流所赋予的价值也不容忽视,据麦肯锡预计,AI为交通领域创造3800亿元的经济价值。
据全球咨询公司麦肯锡发布的生成式AI对全球经济影响力报告,预计如果将其分析的63种生成式AI应用于各行各业,每年可为全球经济带来2.6万亿至4.4万亿美元的增长。同时,约有60%—70%的工作可以通过生成式AI的应用实现自动化。这无疑给所有担忧抛下一个重量级支点: 坚持创新,拥抱未来!
经济学人APP资讯组
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦