博观约取,厚积薄发。
今天,我们继续从patches出发,来看如何构建多尺度的视频统一训练范式。
Sora的技术报告里也明确说了,Spacetime Latent Patches 和 Variable durations, resolutions, aspect ratios 这两段,讲分辨率、时长、长宽比都可变。这个业界其实也有处理方法。我们来把这块盘一下。
今天这个系列共三篇论文。
1.FlexiViT: One Model for All Patch Sizes。这篇文章讲的是一个模型训练多尺度patches。
论文:https://arxiv.org/abs/2212.08013。(谷歌)
代码:
github.com/googleresearch/big_vision.
2.Efficient Sequence Packing Without Cross-Contamination: Accelerating Large Language Models Without Impacting Performance。这个文章讲的是NLP里的长度不一的tokens序列打包一起训练的事情。
论文:https://arxiv.org/abs/2107.02027。(Graphcore.ai)
3. Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution。这篇文章借鉴了2的思想,讲的是图像patches序列如何打包一起训练的事情。
论文:https://arxiv.org/abs/2307.06304. (google deepmind)
代码:https://github.com/kyegomez/NaViT
一、FlexiViT: One Model for All Patch Sizes前一篇文章我们讲过, patches的来龙去脉
论文中,一张正方形图片分成9份。这个分9份还是分4份还是分16份其实是一个超参数。这个超参数还很能影响算法效果的。这样不难理解,分的越细你算法看的东西就越细,精度就高,但速度慢;分的粗,你算法看的东西就粗,蜻蜓点水的话,速度快,精度低。
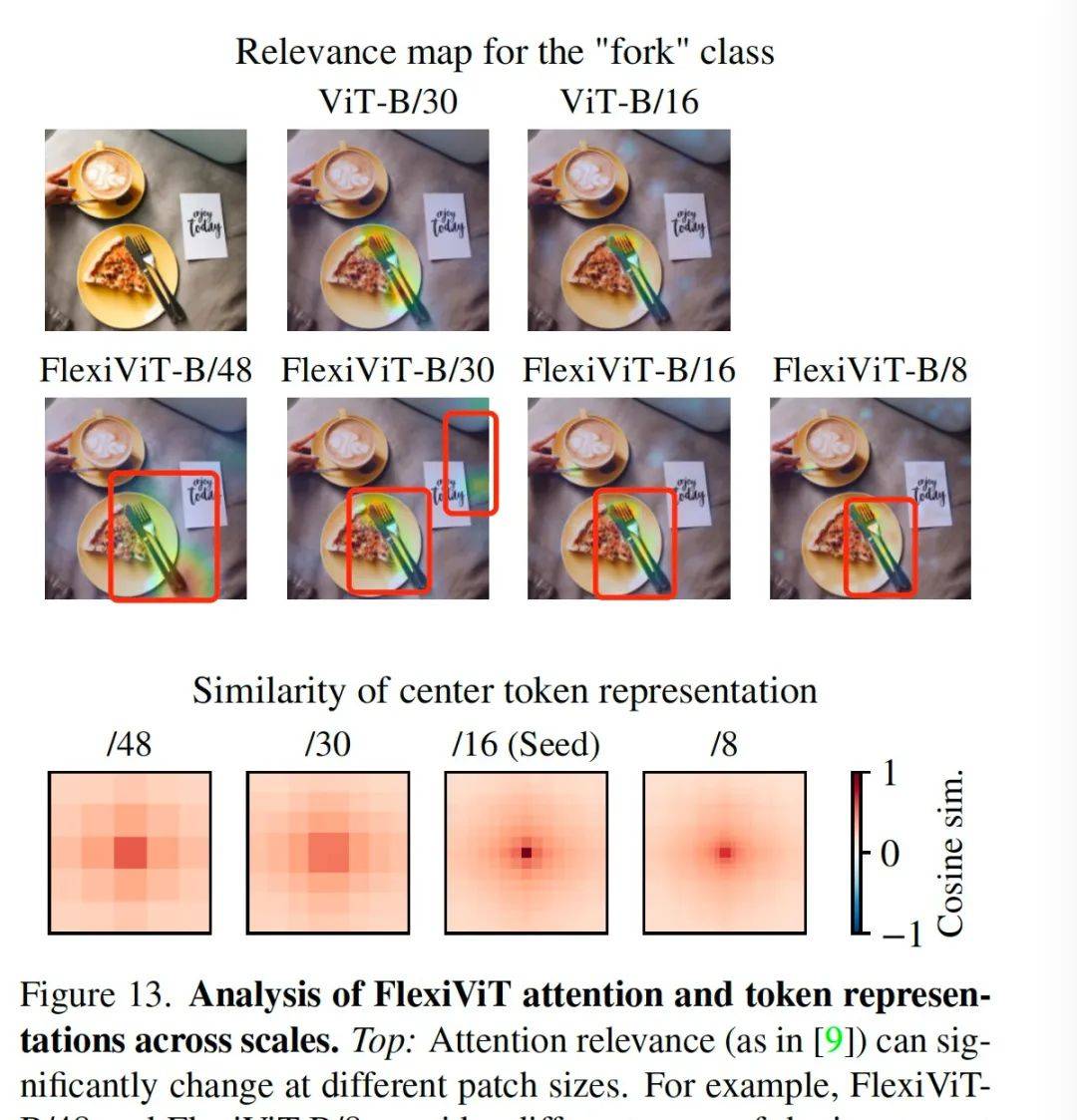
关于这一点,论文中做对比分析的时候有一个经典的图如上,对于分类类别为叉子这个任务,当grid即切割的patch尺寸为48的,响应区域我标红框的地方比较大,相应的颜色为黄绿色的一块区域;当grid为16时,基本就可以将相应区域定格在真正的叉子那一块了。再小为8时基本没有提升了。
这篇论文的核心思想文章中用了一行代码表示:

在训练构建batch数据的时候,随机选一个尺寸(代码中的np.random.choice )来码patches的序列串。这样保证训练的时候是多尺寸的,然后推理的时候也可以支持多尺寸,保证的训练的输入特征丰富性。从而提升效果。
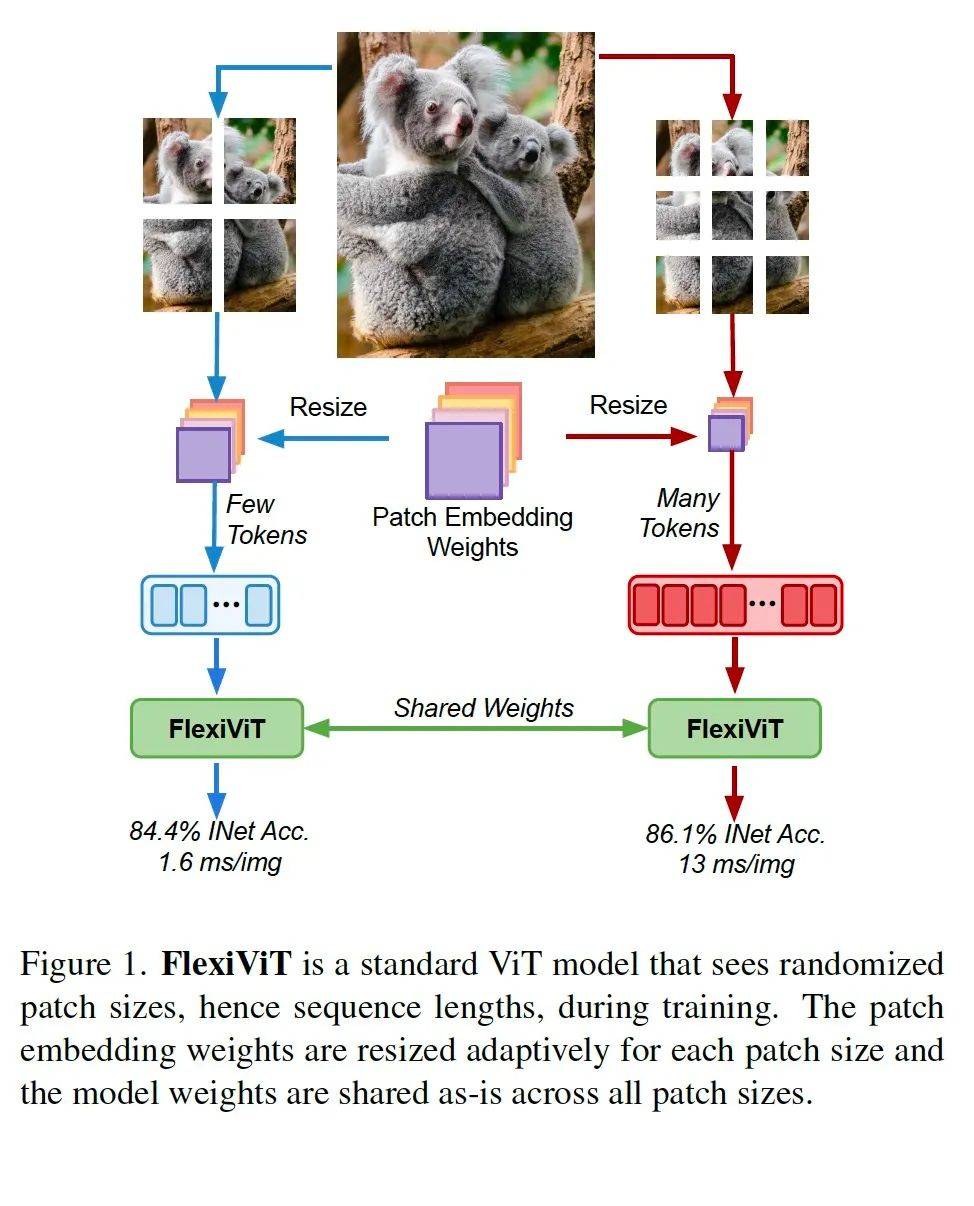
整个pipeline如上图所示。一张图片可以分四份,也可以分9份,然后底层参数共享权重,保证训练推理的一致性。4份的时间是1.6ms一张图片,9份的是13ms。然后概率值也不一样。
小结:
这篇文章中,输入的原始图片尺寸其实是没有变的,都是正方形,只是切分的grid尺寸变了。因此跟sora里讲的输入原始图片可以多尺寸不是一回事。但这篇文章告诉我们,grid要支持多种尺寸,这样的更灵活精度可以更高。
二、Efficient Sequence Packing Without Cross-Contamination这个文章是NLP领域的。本来跟sora没关系。但是,我觉得视频就是一个天然的序列,跟文本序列具有相似性,其次呢,这篇文章的思想是第三篇paper -NaviT的源头,因此应该研究下。
这篇文章的核心思想其实非常简单。因为我们需要把序列tokens对齐,如果一个数据集中,最长的序列是168,然后,那些短序列也需要填充空值到168,拿去模型中训练,这样的话,一方面模型训练速度慢,另一方面收敛速度也慢。
解决方案是,如果一个序列长度是60,一个序列长度是100,那么这两个序列凑到一起,然后只需要填充8个空值就组成了一个168的序列。那么照这样组合,比如有1万个序列,看如何组合使得组成的168序列的个数最少,这样训练速度就最快。这个就是一个启发式经典装箱的问题。论文给出了几个算法。我觉得这些算法都很简单的。就不讲了。
刚才说的只是组团的问题,组完团后,还需要考虑训练过程中attention的分组问题。
论文中也放出了代码:
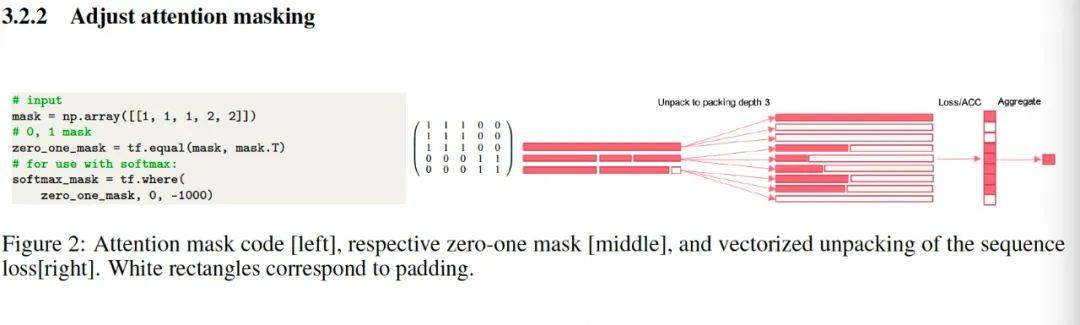
他用一个mask 来做标记。上图中的矩阵,应该表达的是一个序列中,前三个patches是一组,后两个patches是一组。
这篇论文总共50来页,附录里有详细的分析和代码。非常值得细嚼。不过我没来得及看哈。
三、NaViT, a Vision Transformer for any Aspect Ratio and Resolution这应该是最接近sora的公开论文方法了。
这篇文章的native思想跟2 是相同的,就是对图片的长度不一致来做分组,三两个或者四五个图片的patches组在一起成一个序列,跟训练集中最长的序列相同长度(不够就加点padding)然后拿去训练。但他也还针对图像问题做了些优化。
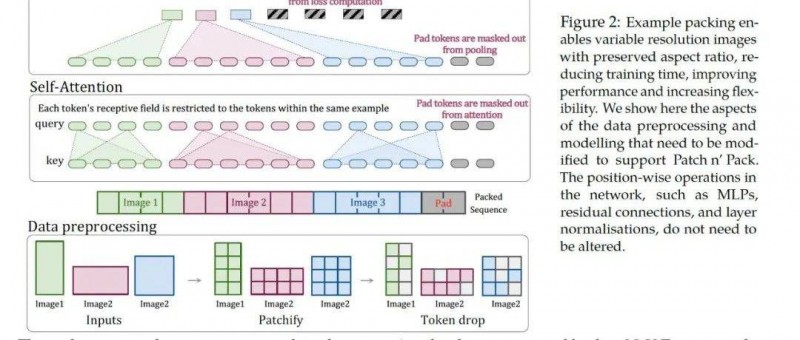
整个pipeline都在这个图里。我们来详细讲解这个图。
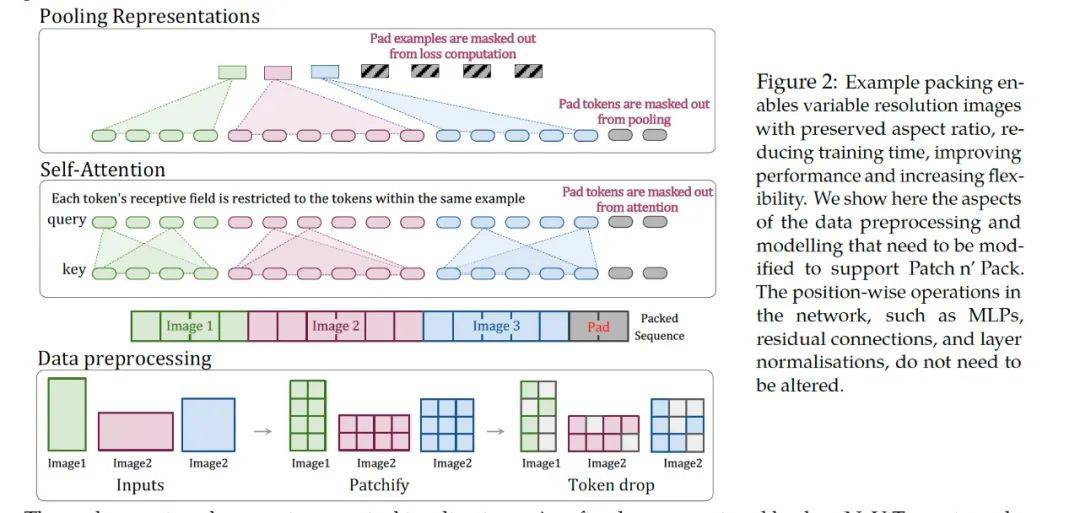
这个图需要从下往上看,第一部分,数据预处理的时候,长大于宽的图片、宽大长的图片、正方形图片,都统一编码为各不一致的patches,然后他做了一个随机丢弃的token drop操作,这个操作就类比于经典CNN里面的dropout层。目的是提高算法的鲁棒性的。预处理完后,把三张图片生成的patches拉平为一个序列,不够的地方用pad填充。
往上走第二部分self-attention部分,这部分讲的是mask self attention,由于有mask 的作用,他可以分块各算各的,就是三个图片不要搞混在一起了。
往上走第三部分是pooling。这部分讲的是将self-attention计算好的特征,通过mask pooling,各算各的。
整个论文讲的就是图片无论各种尺寸,只要是计算过程中加上mask,就在一个小模块里可以单独计算单独处理,不影响整体的input shape 和 output shape。从而达到了多尺寸全分辨率统一训练。
另外,由于他随机丢弃了一些patches,因此算法的鲁棒性和速度也变快了。
总结这篇文章我们全面盘点了如何构建一个输入图像多尺度多分辨率的统一训练范式,同时也highlight了一下 FlexiViT。他也许是能提升算法精度的一个方法。
多看paper。勤敲代码。临渊羡鱼,退而结网。不惧悲喜,只争朝夕。
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦