OpenAI真是一家伟大的公司。他做出GPT不是一个偶然,整个体制机制非常有利于专心做事的人。除牵头人外,Sora团队都是入职一年内的人,做出如此出色的成果,说明整个机制出现了竞相涌现的良性循环。国内的AI实验室估计一年写自然基金项目的申请本答辩都费劲。
从今天开始逐步的将sora周边的论文梳理一遍。围绕核心组件抽丝剥茧。先把逻辑盘清楚。
Sora技术报告里面提到自己对图像构建了一个类似于NLP里面tokens的概念的东西,取名为patches。今天来盘这个组件。
事实上,patches在几年前的论文里就有。我盘了下几篇经典的关于patches的论文。分别为:
ViT- an image is worth 16X16 words (Google, 2020.10,ICLR2021)见参考文献[1],
ViViT: A Video Vision Transformer (Google, 2021.03)见参考文献[2],
MAE -Masked Autoencoders Are Scalable Vision Learners (meta, 2021.11) 见参考文献[3]。
一、VIT-patches的起源An Image is worth 16*16 words:transformers for image recognition as scale
这篇文章是patches的源头。第一次有人将图像编码成一个个序列单元patches。他之所以这样做,是因为他想用transformer 做图像分类,CNN可以直接对图像自动分块边卷积边滑动,而transformer需要输入的是带位置编码position embedding的序列数据。因此文章为了解决这个gap,手动对图像进行了分块和打位置编码。发现效果很好。
接下来由浅入深讲一下他的做法:
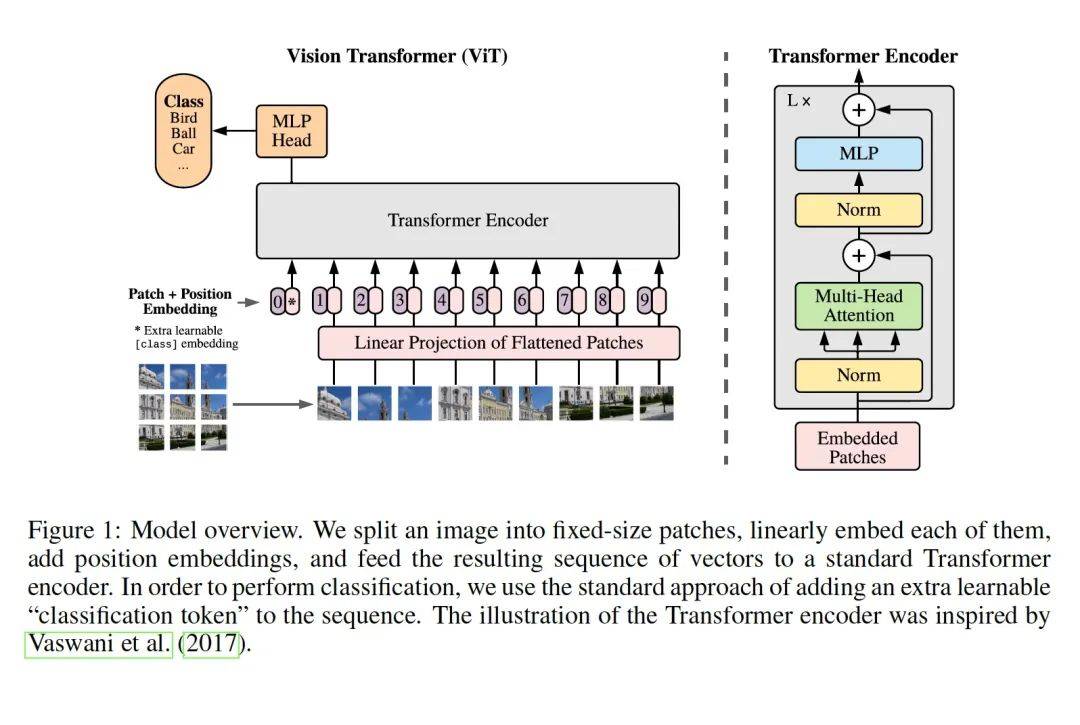
整个算法结构图如上。虚线左边是整个pipeline。右边讲的是左边一个模块 transformer encoder。他的方法非常简单,就是手工将一张正方形图片切割为9份,然后将每个小方块图片的特征和位置编码(1-9)作为transformer的输入,同时,他借用了berts的[class]token的做法,将图片的分类类别名作为0位置的编码,一起组成embedded patches 输入到transformer来做分类。Transformer只是用了编码器,然后将编码器得到的特征通过一个MLP层做分类。
二、ViViT: A Video Vision Transformer这篇文章讲的是用transformer来做视频分类的任务。
编码视频的时候,存在很多跟编码图片不一样的地方。一个方面是量大,一个视频一秒就是30帧图片。另一个方面是,视频有时域的概念。就是前一帧和后一帧同一个位置是有信息熵的。代表了前后的变化,同时合成视频的时候要保证前后变化的连贯性。这些也是视频的核心信息。
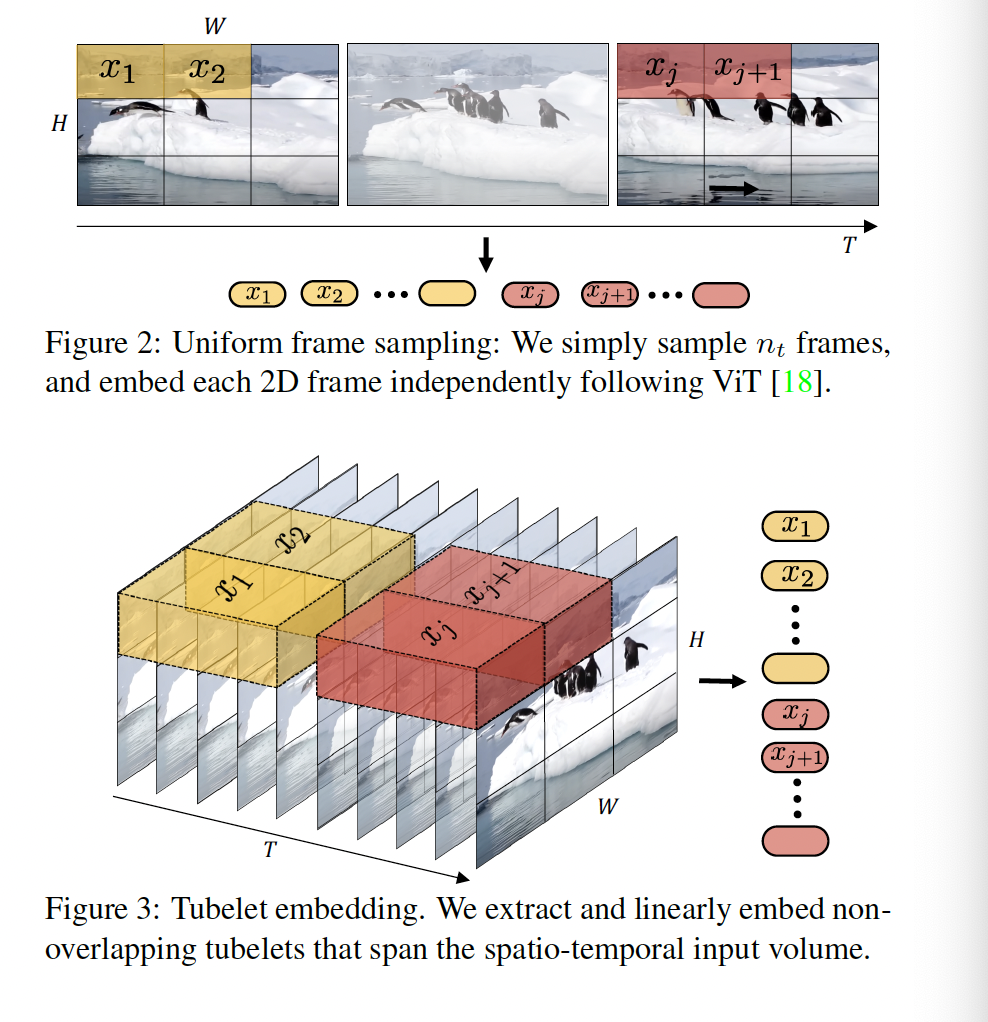
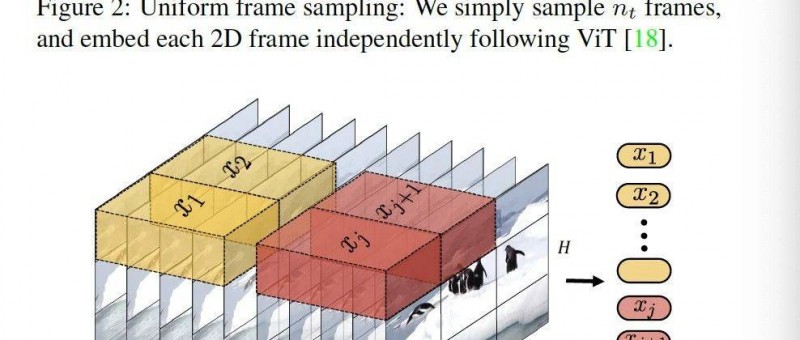
整个编码过程如上图所示。他的整个编码过程是很简单的。单图片的编码跟VIT里的一样。就是手动将一张图片编码成1-9个小patch。然后,由于是视频,就将他们按时间戳码好。由于有时间这个维度,所以码出来就是一个立方体。
这篇文章核心的贡献是设计了4个视频transformer编码器。他的设计思路也非常简单,主要逻辑是在空域和时域上做一些变化。
1、时空注意力模型。
这个就是最原始的方法。他没有做任何创新,直接将码好的立方体输入进transformer,这样的话,时域和空域之间每部都会交叉提取特征。计算量会比较大。
2、分步编码。
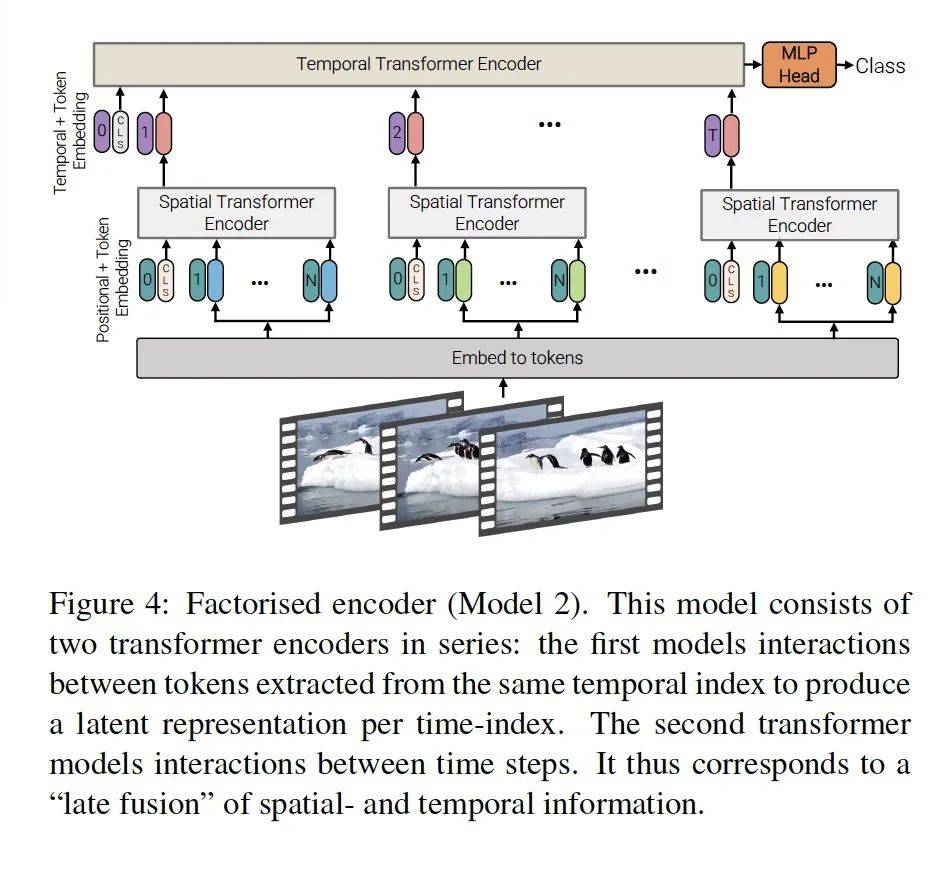
这个模型的方法主要是分了两步。如上图,输入初始编码好的tokens后,第一步他构建了一个空间的transformer Encoder。然后再接一层时域的,Temproal Transformer Encoder。最后接一层MLP的分类器。
3、model3 分步自注意力机制。
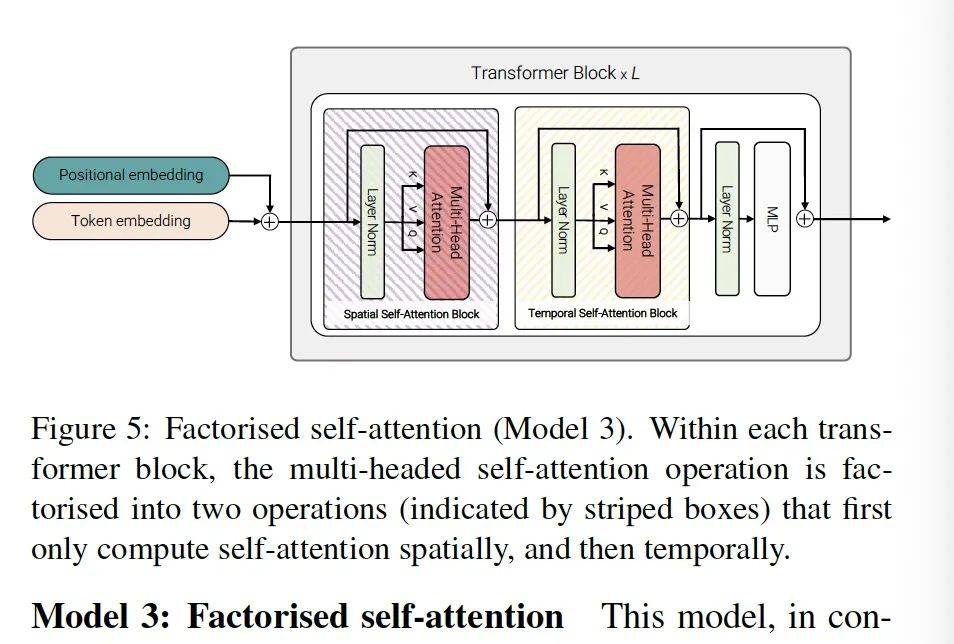
这个模型的变化是操作粒度缩小了。Model2的分步操作在transfomer编码器那里。Model3的 分布操作在多头注意力机制层中。他只有一个transformer,但他有两个自注意力模块,一个空间自注意力模块,一个时域自注意力模块。然后接上层归一化,再接一个MLP做分类。这样的话他节约了不少transformer内部的通用层。
4、model4 分步点乘注意力机制层。
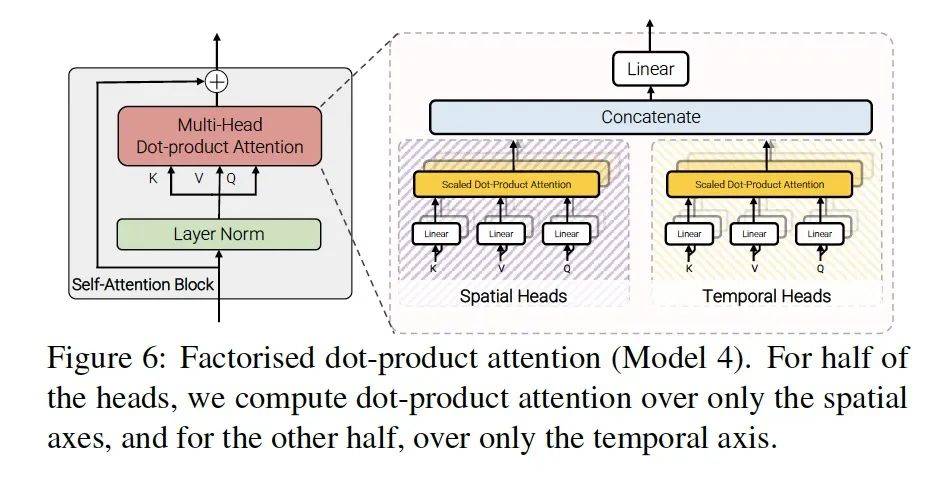
点乘注意力机制:这个我好好解释一下什么叫做点乘注意力(dot-product)。
假设A矩阵是上层输入的特征参数,不是矩阵也可以,你可以是三维、四维向量。我操作的时候只取那个截面矩阵。那么A矩阵这些参数他的重要性我觉得应该根据反向传播的信号来学习,假设重要性最高为1,有的参数重要性高就趋近于0.9,有的参数重要性低就趋近于0。但具体是多少呢,我需要用一个跟A同秩的矩阵W参数去表示,然后这个W矩阵是根据反向传播信号是可以学的。这就是点乘注意力机制。这个点乘注意力矩阵就是W。
Model4的方式就是一边做空间点乘注意力,一边做时间点乘注意力,然后再将两者融合在一起加一个线性层,作为transformer的多头注意力机制的模块。
总结通过梳理,我们明白了patches的由来。包括图片和视频的patches编码方式。同时,如何通过patches构建一个预训练任务。对比GPT预测一个token,图像的预训练可以是预测一个patches,然后视频的话,可以是预测一组patches。这样的预训练任务就可以保证生产出的视频具有连续性。
因此,可以大胆推测下,要构建一个sora,应该先有一个图像预训练的模型做底座。
参考文献:
1 .Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ArXiv abs/2010.11929 (2020): n. pag.
2. Arnab, Anurag, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lucic and Cordelia Schmid. ViViT: A Video Vision Transformer. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) (2021): 6816-6826.
3. He, Kaiming, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollar and Ross B. Girshick. Masked Autoencoders Are Scalable Vision Learners. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021): 15979-15988.
4. Dehghani, Mostafa, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim M. Alabdulmohsin, Avital Oliver, Piotr Padlewski, Alexey A. Gritsenko, Mario Luvcic and Neil Houlsby. Patch n Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution. ArXiv abs/2307.06304 (2023): n. pag.
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦