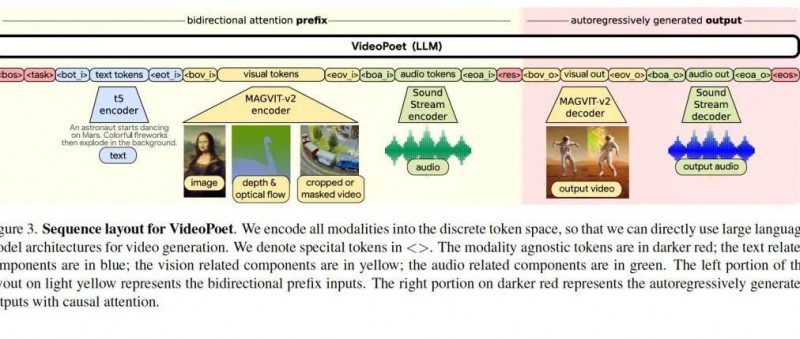
今天我们来正式研究谷歌的最新视频合成论文videopoet: A Large Language Model for Zero-Shot Video Generation。这篇论文是一个划时代的产品,之所以这么说,他有两个核心贡献:1、将文本、视频、图片、音频统一编码成一个codebook空间,然后用LLM那套训练范式训练。2、效果上,他可以合成5秒(41帧)的视频,核心突破是它可以保持运动的一致性。这一点( motion)很难,因为人类对动作连贯性很敏感。稍微有些别扭就觉得视频很假。
这篇文章的方法可以说跟Sora差别很小,像文本视频音频统一编码就完全是一样的。核心差别在于训练任务的不一样上。Sora跟 李飞飞他们的工作WALT [4] 是一样的,就是在训练任务上,一个扩散模型;而videopoet是一个mask自回归模型。
这两种范式各有千秋,前一种合成图片视频的真实场景逼真度更高,后一种方法合成视频音频的连贯性更好。应该结合起来一起用。
之所以有这样的区别,我仔细思考了下背后的数学逻辑:前者的diffusion扩散模型,他是针对原图增加高斯噪声,然后让模型学习去燥,这样模型更能学到逼真度高的画卷方法,他让模型去学习了像素的真实分布规律。这一点我多讲一句,我想起学校生涯的时候导师研究隐写分析的领域知识,就是将一张图片里的一些像素值改掉,然后让检测器检测出来哪些图片有篡改,哪些没有。那么这个扩散模型其实就是干这个活,只是不是手工篡改像素值,而是利用高斯噪声来篡改像素值。而后一种mask回归任务呢,他主要特征是前一帧预测后一帧,或者是图片中心预测整个四周,四周预测中心或者左边预测右边这些任务,他整个任务设计的就是next token的意思,当然就主要学习视频的连贯性了。
因此,sora你可以理解为WALT的改进版。并不神秘。模型结构变大了,然后数据变多了,然后更高清了。效果更好了。后面我们再研读WALT。
言归正传。我们来正式解刨videopoet。这篇文章知识密度很高。我看了好久才搞懂。

scaling law的正确姿势:训练videopoet需要多少GPU
我们来认真盘一下这个事情。他也是大家很关心的事。
Mask模型本质是一个分类器,预测next token是什么。经典图像分类工程中,imagenet数据集,共1000个类别,你可以认为是token的cookbook是1000 的size,然后总数据集是128万,合每个类别1300张图片的样子。这个类比的意思是,一个token的全分布概率计算,需要1300个样例来统计。
GPT1的词典大小是40,478 个,GPT-2的词典大小为50257个,因此词典差别不是很大,那么我们姑且假定GPT4的词典大小为6万,他的数据集呢,是13万亿个 token,也就是每个token有2亿个样例来计算全分布概率才能达到GPT4的效果。
题外话:
大模型之所以大,核心问题就是词典大小太大,导致最后一层的预测softmax层参数巨大,需要大量的样例才能将这些参数完整训练出来。因此造成了大的资源浪费。我觉得这个是一个巨大的bug。是否可以分层分group分步执行,将这个计算量降低,因为本来就不符合逻辑,这么巨大的cookbook其实不符合人类的认知逻辑的,我们会将礼拜天和星期日当一个token,而LLM的话就是两个,其实是可以压缩的。
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦