我们在探讨patches的方方面面。不过patches有一个核心bug:就是他的分片是简单切割的,比如一张图片切成9份,那么有可能,一个具象的语义信息,例如一个人脸,可能被切割在了四份里面,每一份都只是人脸的一部分,这样的特征提取器表达力肯定是不完整的。
在NLP中,有一个专门的分词器tokenizer。例如可以把满腹经纶这样的成语分为一个词。如果图像要套用NLP里面的tokens的概念。这样的图像语义分词器就显得非常重要。
业界对这块也研究了很多。今天我们这条线盘一盘。目前我们整个系列还在盘图像tokens这个概念,他只是整个知识树的一个根,后面我们再整体全貌看如何构建一个视频生成网络模型的pipeline。
今天分享三块:
1、VQVAE Neural Discrete Representation Learning。如何将图片编码为离散隐变量。
论文:
https://arxiv.org/abs/1711.00937。这个是(google deepmind 2017 NIPS)
代码:https://github.com/karpathy/deep-vector-quantization
2、VQGAN Taming Transformers for High-Resolution Image Synthesis。他的核心思想是把VQVAE里面的CNN换成transformer。
论文:https://arxiv.org/pdf/2012.09841.pdf。这个是CVPR2021 oral。德国人的。
代码:https://git.io/JnyvK.
3、MAGIT - Masked Generative Video Transformer。这个论文是在VQGAN的基础上首次合成视频。
论文: https://arxiv.org/abs/2212.05199
Project : https://MAGVIT.cs.cmu.edu/
代码: https://github.com/google-research/magvit
一、VQVAE 图像的离线隐空间编码器这是一篇高被引奠基性的文章。后面很多论文都在这个论文基础上展开。他的核心思想其实也很简单。附上论文原图。更加真实理解论文本意。
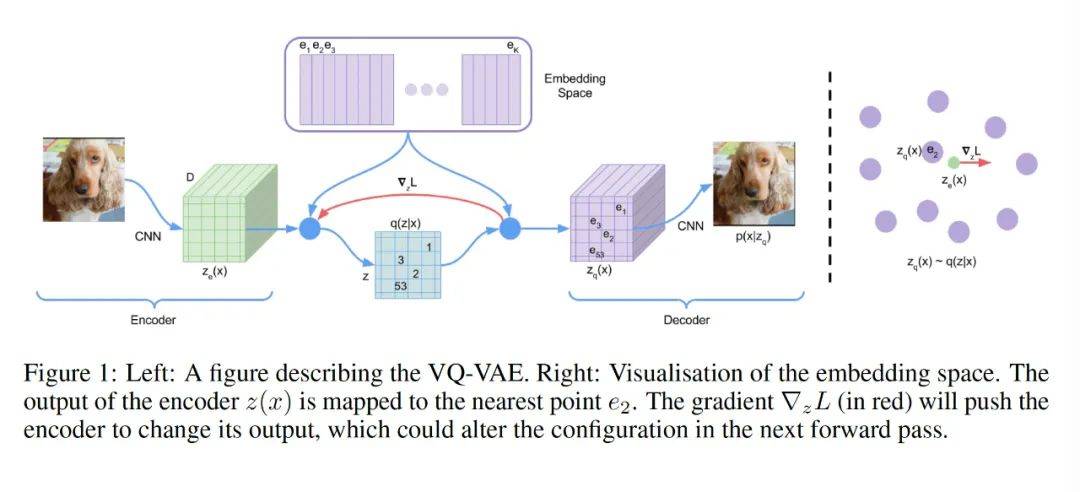
整个pipeline在上图中。我们详细讲解一下整个过程。整个图从左往右看,虚黑线隔开的右半角部分是讲如何最近邻搜索离散化的。一只小狗的原始图片,通过一个CNN编码器网络,转变为一个隐变量绿色立方体空间Ze;由于是神经网络非线性变化,Ze肯定是一个连续变量空间矩阵,这时候,通过一个特征空间查找表E,将Ze里面的连续值,通过最近邻算法查找到最相近的点ei,从而将绿立方体变成了浅紫色立方体特征空间Zq。然后对这个浅紫色特征空间进行CNN的解码器变换,变换出一个真实图像出来。如果编码器学的好,就说明这个特征表示Zq非常有效。我们就拿这个Zq来表示这个图片了。由于Zq是离散值,因此就是一个图像的离散特征表示。红线表示的是梯度传播的时候直接跳过离散化查找表。
整个loss共三项。

第一项很简单,x是输入的图像,Zq(x)是解码器输出图像,这个就是一个重建loss,看输入的原始图像和解码器输出的图像之间的loss。后两项看起来比较复杂。我通俗易懂的给大家解释下原理:这两个loss的目的是让离散化查找表embedding space 中的节点更内聚的。所谓内聚,就是,以这张图为例,你可以把狗的耳朵当成一个离散值节点,那么两个狗耳朵就不需要两个离散化节点了。这样就提升了离散节点的表达力。他就是NL P里面词表的概念。
二、VQGAN : VQVAE的改进版这篇论文有很多的博客在讲。但很多人都讲错了。VQGAN他的编码器和解码器都是CNN,并没有变化;他之所以命名为VQGAN,核心的区别是他的解码这一块,就是隐空间特征生成图像这块,他用的是GAN:有两个CNN,一个生成式CNN生成图像,一个判别式CNN对生成的真假打分。所以说他整个pipeline是没有transformer的。并不是编码器和解码器变成了transformer。
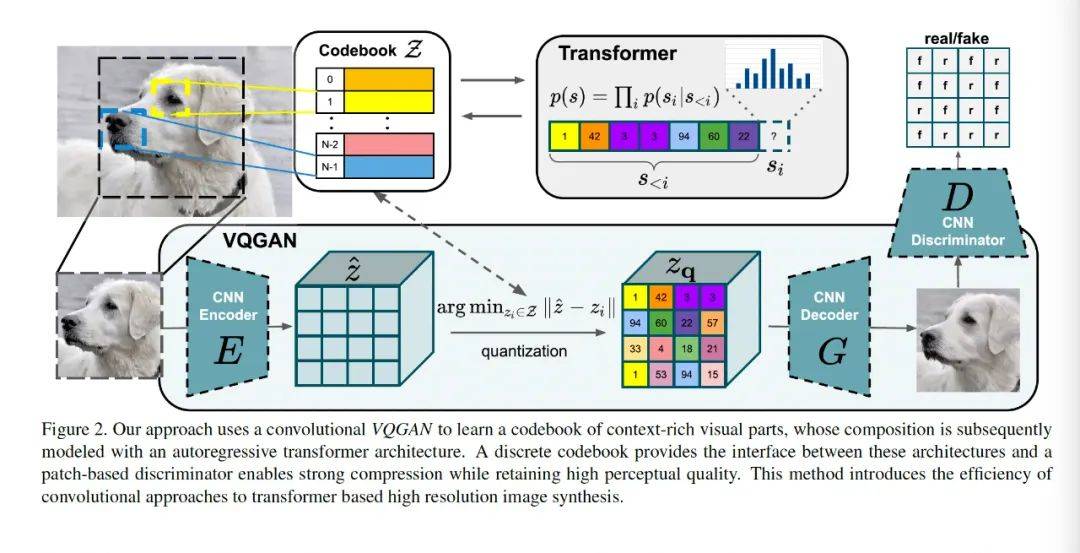
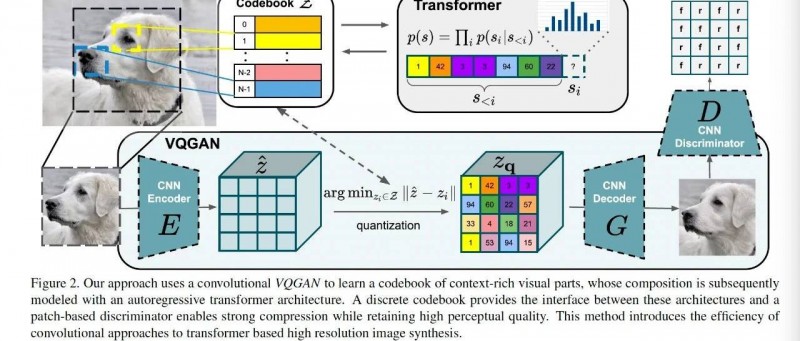
整个pipeline如上图所示。从左到右看,下面一层就是VQGAN的整个pipeline,img到编码器CNN,然后通过图像分词器tokenizer转成 Zq,然后再通过GAN生成img。整个pipeline有三个CNN。编码器cnn encoder,解码器CNN decoder,然后是判别器CNN。
Transformer干的是哪个活呢?是对分词器的优化,和对Z- Zq表示的优化。在VQ VAE中,分词器就是一个pixel CNN,当然这个也算是比较好的表达方式,如果你学过数字图像处理这个课,最原始的图像离散化表示是超像素分割。Transformer第一作用的生产出最具有表达力的图像词汇表;第二个作用是,当前的图像,用了词汇1-i-1共i个词汇后,还需要哪个词汇(图像语义token),能更好的表达当前的图像,从而生产出最具有表达力的Zq。
事实上,这个transformer表达的分词器词汇表对整个模型来说非常关键。
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦