DeepSeek证明了另一条路的可行性
@松果财经原创
OpenAI 在2月1日正式上线o3-mini系列模型,号称要推动低成本推理的边界,并且首次向免费用户开放了推理模型的权限,显然是为了对冲DeepSeek的影响。而与此同时,DeepSeek正处于冰火两重天之中。
一方面,据中新社、澎湃新闻、环球时报等媒体报道,DeepSeek遭遇多方围剿,美国等国家从数据安全、个人信息等方面出发,对DeepSeek进行或明或暗的限制。
此外,奇安信Xlab实验室监测发现,1月30日起,针对DeepSeek的攻击烈度突然升级,较1月28日暴增上百倍。其中至少有2个僵尸网络参与了攻击。僵尸网络指的是攻击者用恶意软件感染和控制其他设备,比如电脑,组成设备网络,再控制这些设备进行攻击。

本次攻击大约起始于1月初,早期为低强度攻击,1月27日左右开始升级。到1月30日,有用户称,从半夜开始DeepSeek卡顿程度剧增,且需要频繁退出后重新登录才能使用。
来自奇安信XLab实验室的安全专家表示:僵尸网络的加入,标志着职业打手已经开始下场,这说明DeepSeek面对的攻击方式一直在持续进化和复杂化,防御难度不断增加,网络安全形势愈发复杂严峻。
据鞭牛士报道,DeepSeek周二向美国专利商标局提交了AI聊天机器人应用、产品和工具注册商标申请,但一家总部位于特拉华州的名为Delson Group Inc.的企业抢先申请了DeepSeek商标,而后面这家公司的创始人Willie Lu和DeepSeek创始人梁文锋是校友,双方都毕业于浙江大学。
另一方面,DeepSeek正在极速改变现有AI应用生态,并成功在全球用户心中留下了深刻印象,尤其是削弱了OpenAI的影响力。因DeepSeek股价大跌的英伟达刚刚推出采用DeepSeek R1 671b的NIM微服务预览版开发工具;微软一开始说明正在调查DeepSeek以不正当方式获取OpenAI的数据,但又迅速在Azure上部署了R1模型,且为免费使用。
和DeepSeek遭遇攻击的新闻放在一起对比,各方心态十分明显:
对OpenAI来说,DeepSeek虽然规模不对等,但却打了它个措手不及;对微软等大企业而言,DeepSeek的开源策略非常符合它们的应用需求,它们虽有自己的立场,却也需要削弱对OpenAI的依赖;对更多AI领域的中小企业、个人用户、爱好者来说,DeepSeek宛如用农村包围城市的打法解决了算力围城问题。而对整个行业来说,DeepSeek公开了一条不同的技术路线的可行性,即单纯利用强化学习(RL)进行自我迭代:
传统方法的RLHF,也就是基于人类偏好的强化学习,让人类为AI打分。预训练撞墙后,推理变成了模型能力提升的关键路径。OpenAI在去年第三季度以o1和后来的o3模型都沿着这条路径探索。但OpenAI并没有公布技术细节,而DeepSeek R1开源后,业界收获了首个完全公开的模型,也证明了RL路线的潜力。
至于商业层面,知名分析师郭明錤表示,DeepSeek R1的出现,让两个趋势更加值得关注--一个是Scaling Law放缓后AI算力的优化训练,一个则是被讨论得最多的成本问题,Token价格越来越便宜,AI应用多元化发展才会更轻松。这是生成式AI效率突围期的转折点。
具体来看,DeepSeek把两个行业核心问题摆了出来。
第一个是开源即壁垒的思路。OpenAI等公司的闭源路线是一种技术壁垒,但DeepSeek将核心技术即时开源,同样构建了一种壁垒。当我用询问DeepSeek这样做的好处时,AI生成的回答是:
这种看似激进的决策实则构建了双重优势,既通过开发者生态快速建立行业标准,又借助低价策略扩大市场渗透。这本质上是在技术扩散过程中抢占生态位,当更多企业基于其框架开发应用时,底层技术的价值反而会持续强化。
事实上,meta对DeepSeek的反应其实最为兴奋,因为DeepSeek用另一种方式证明了meta的开源思路有正确性,而且还提供了非常多的参考资料。有媒体日前报道称meta在DeepSeek的突破中看到了希望。meta副总裁Ragavan Srinivasan直言:我们的开源策略得到了验证,有更多人能够获得推动事物更快发展的技术,就越好。
并且,meta通过社交媒体广告赚钱,反哺AI开源,而DeepSeek也是背靠幻方量化,有支撑AI发展的资源。meta作为唯一一家走开源路线的美国大型公司,其做法体现了防御性,在相对安全的情况下用成熟商业的资源换取AI发展。而DeepSeek作为创业公司,则明显更加积极。
一位海外用户对此评论:托马斯弗里德曼2005年的著作《世界是平的》,描述了互联网如何在全球范围内传播知识。我猜中国人学会了如何在我们先进的地方打败我们。(指用开源竞争闭源)
另一组评论更加发人深省,DeepSeek将改进的成果免费带给了全世界,即便是美国的初创企业也开启了下一个阶段,这才是技术普惠的双赢:Open means worldwide.
第二个是AI的发展效率,DeepSeek选择了一条差异化的技术路线--在保持模型参数规模可控的前提下,通过动态调整计算强度来提升效率。这相当于为AI系统安装了智能调节器,使其能够根据任务需求自动匹配运算资源。这种思路打破了参数越多越好的固有认知,证明通过算法优化完全可以在不增加硬件投入的情况下实现性能突破。
需要注意,这并没有否认先进大规模GPU和优质数据的价值,但对于广大缺乏资源的开发者,以及想要跳出生成式AI既有缺陷的玩家来说,这一次尝试的意义很大。
之前,OpenAI因为高昂的定价被市场诟病,SemiAnalysis在前两天刊发的DeepSeek事件分析报告中指出:R1 并非从技术层面削弱了 o1 的进展,而是以更低的价格实现了相当的能力。OpenAI之所以能定高价,是因为它们一开始基于最前沿的技术定价,然后享受溢价,而R1达到了类似的能力水平之后,OpenAI就不得不做出反应。后续能力定价依然会是关键因素,每一代能追赶上领先能力的参与者越来越少,同时一旦追赶成功,带来的影响也就越大。
这也是影响到二级市场投资的主要因素,也就是郭明錤提到的,过去这两年,市场投资AI产业链是Scaling Law对服务器和GPU的需求,然后推动出货量增长。DeepSeek则证明,Scaling Law放缓之后,关注其他提升模型效益的路径,也是投资机会。
因为AI的成本足够低,相关的应用才会获得更大的试错空间。在AI成本很高的时候,应用的收入增速可能还赶不上成本的增速,也就没办法形成可行的盈利模式。而随着成本下降跌破一个又一个关口,算法其实代偿了之前必需的一部分成本,所以真正的创新爆发必定会延伸到应用层。
而这又延伸出两条思考:第一,AI应用需求越多,是否最终依然会提升对算力的需求?算力池总量扩大,依然是潜在的逻辑。第二,这些相对便宜的AI产品有机会促进端侧AI和Agent的发展,怎么兑现还有待探索,因为单纯便宜还不能解决AI落地的所有问题。
OpenAI在1月23日发布了智能体Operator,也就是Agent,可以完成订餐、电商购物之类的任务,但后续热度很快被DeepSeek相关话题盖过。OpenAI虽然认为这种日常任务自动化蕴藏巨大机遇,但Operator功能被放在每个月需要200美元的ChatGPT Pro订阅中,显然并不觉得现在有低价推动Agent普及的必要。
但如果更低成本的AI得到进一步开发,相关的应用必然就会加速。并且DeepSeek作为贯穿整个农历新年的全球性热点,因其语言方面的能力突出,特别容易被普通用户发现亮点,又成功席卷所有平台的头条,所以对之前没有使用过AI产品的用户的吸引力,也是独领风骚。
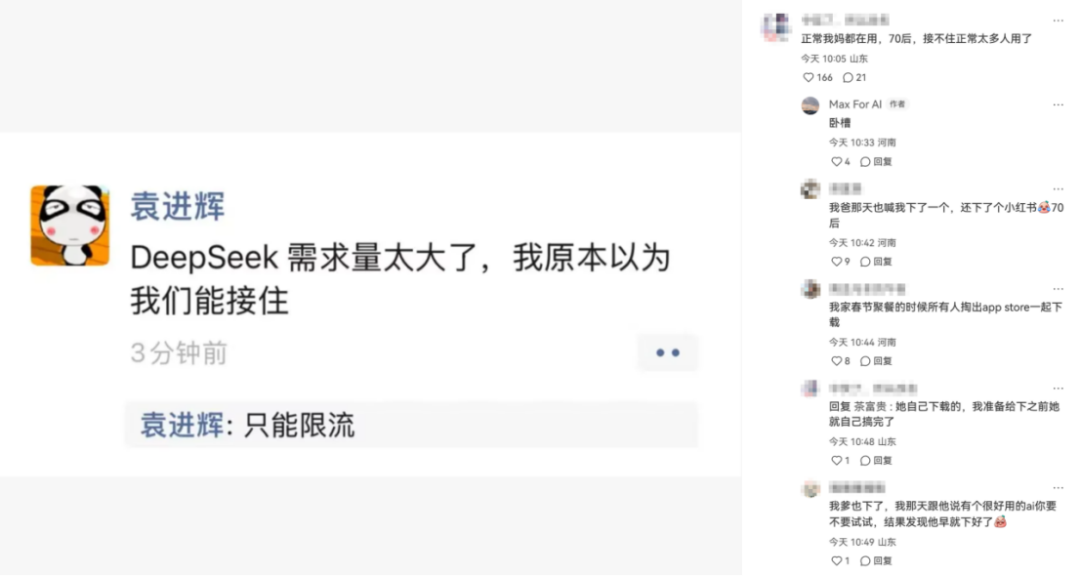
2月1日,硅基流动和华为云团队合作,联合首发并上线基于华为云昇腾云服务的DeepSeekR1/V3推理服务。随后硅基流动 CEO & 创始人袁进辉在朋友圈表示,DeepSeek需求量超出预期,只能限流。
总之,无论是在使用体验上,还是技术路线上,亦或者行业发展水平上,DeepSeek都做出了令人意外的贡献。它所遇到的一切,也就不难理解。
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦