前几天,AI 创作者海辛在 X 上发了一个巨物宝可梦的视频,播放量 120W+,爆火了。
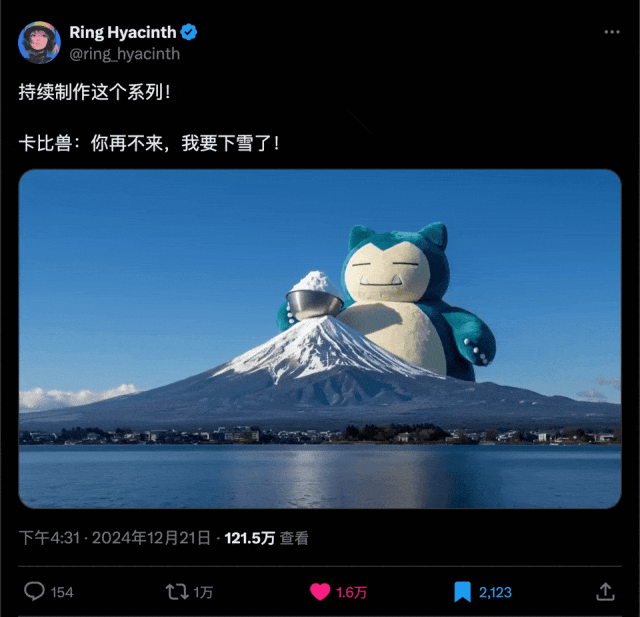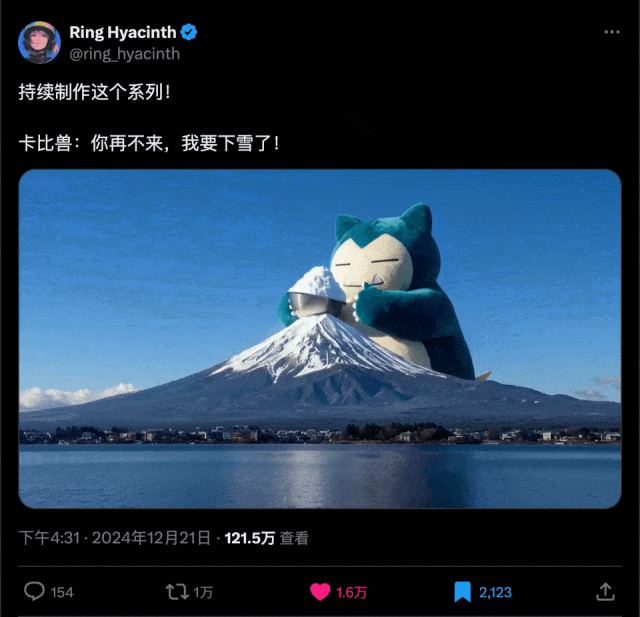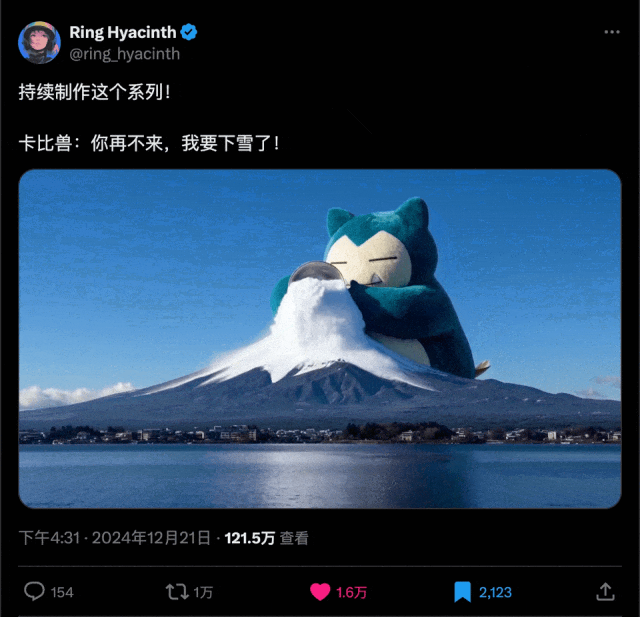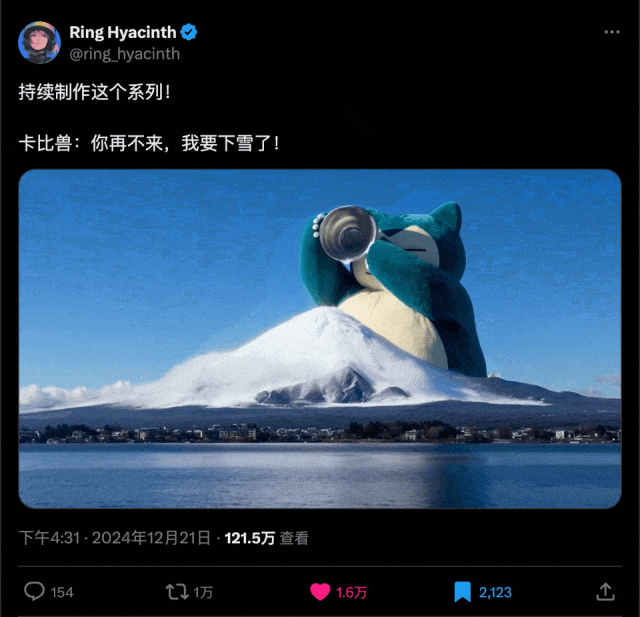
网上好多人模仿,也有很多人好奇这种视频怎么做的。
我尝试做了几个视频,实现思路:用 AI 出图,再用 AI 以图生视频。关键是生成的图片效果要好。
之前的 AI 生图工具,想生成这样效果的图片,对提示词要求很高,效果还不稳定。
能快速模仿,正是用了 Whisk 生图,再用可灵 AI 生成视频。
我体验发现,Whisk 实在太好玩了,操作简单、效果好,连提示词都可以不用写,产品设计还特别值得学习,赶紧跟你们分享。
先看看 Whisk 怎么玩?
打开 Whisk 首页,你只需上传一张图片,或拖拽页面上的图片到主题框里,不到 1 分钟即可看到效果。
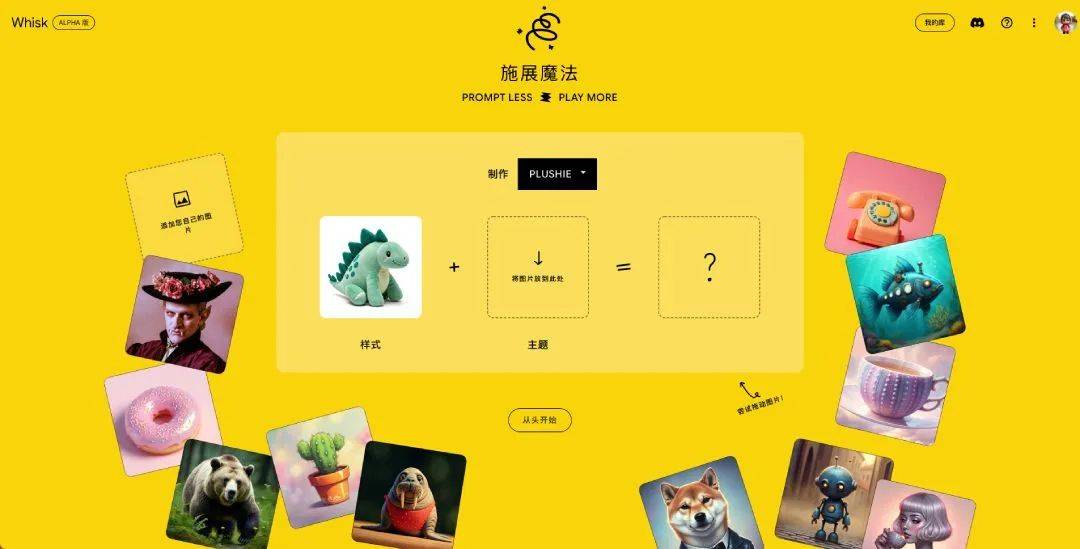
Whisk 提供 3 种默认风格:贴纸、珐琅别针和毛绒玩具。
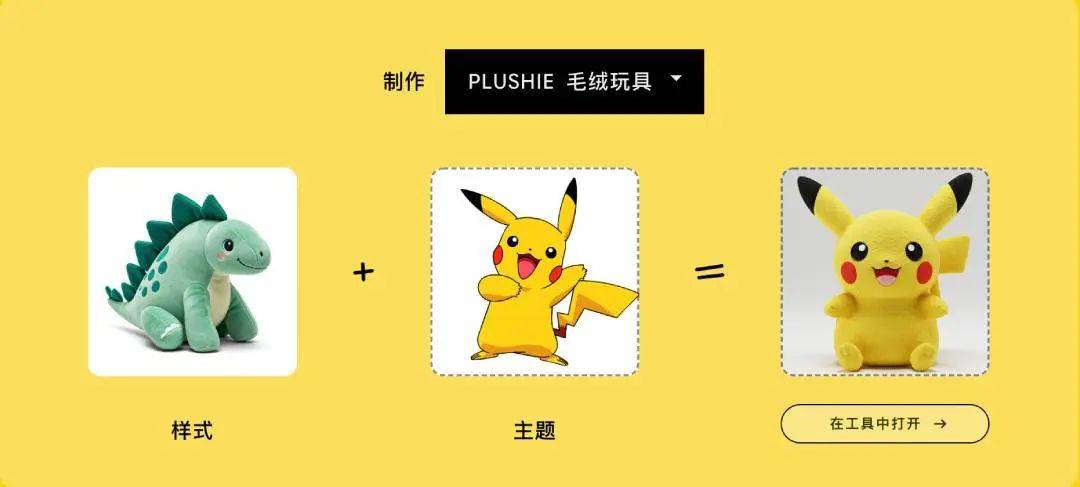
你看,提示词都不用写,直接出图,效果不错吧?用头像生成毛绒玩具,几乎可以直接定制自己的公仔了。
这,只是 Whisk 的简化模式。
如果你想做一张更好玩的图片,点击在工具中打开或从头开始进入完整模式。
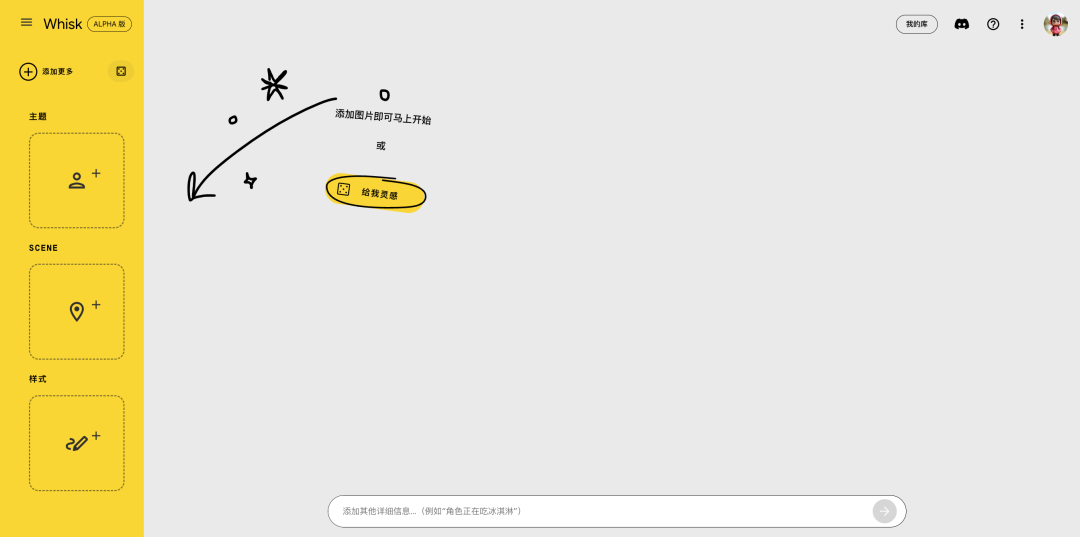
界面非常简洁,重点在左边,可以分别上传主题、场景和风格 3 种图片。
你可以只上传 1 或 2 张图,也可以在每个主题同时选多张图片,非常灵活、可玩性很高。
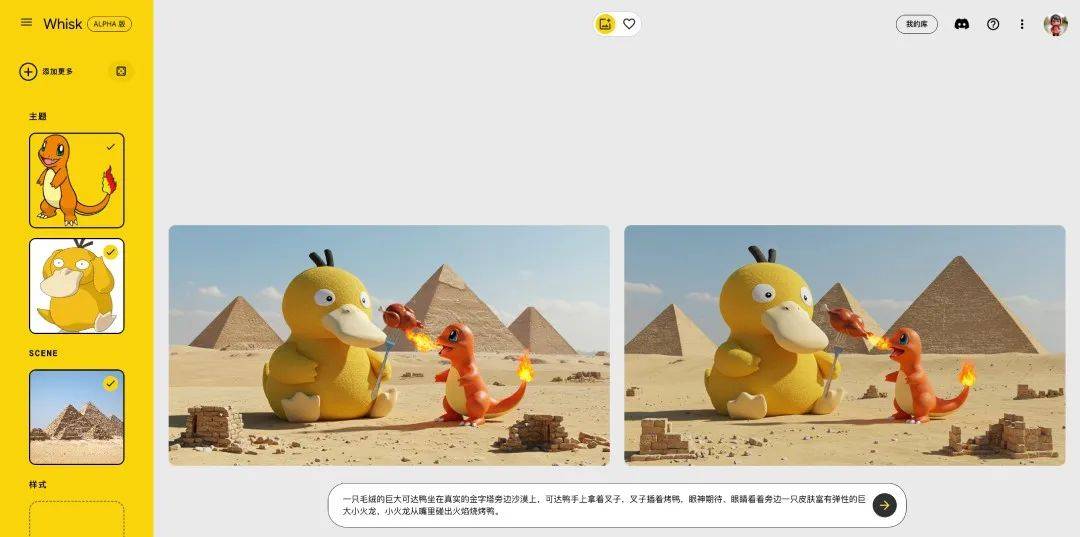
比如,我让小火龙给可达鸭烧烤鸭吃。
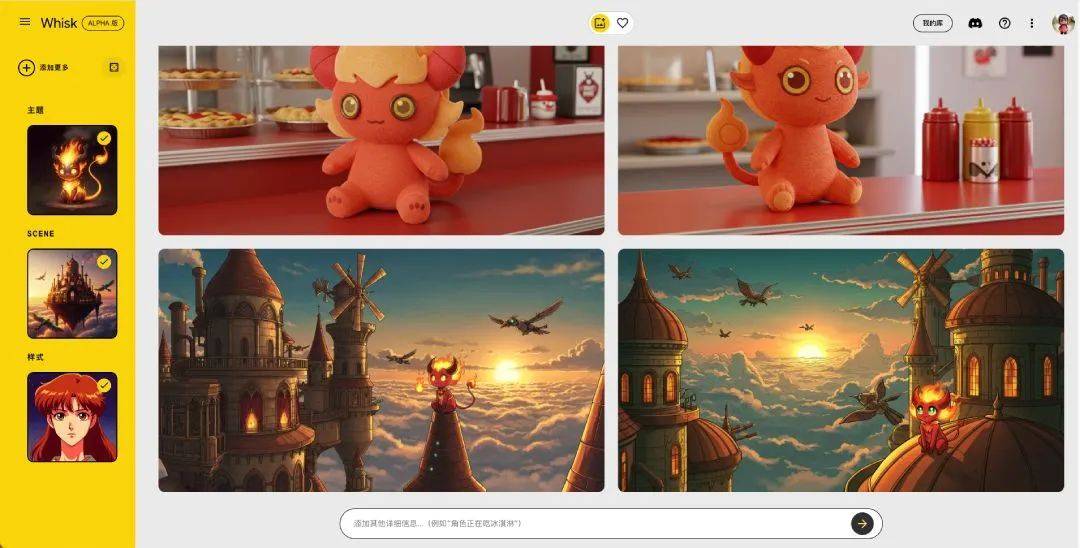
如果你不知道做啥,可以点击掷骰子,Whisk 随机出一些图片,帮你找灵感。
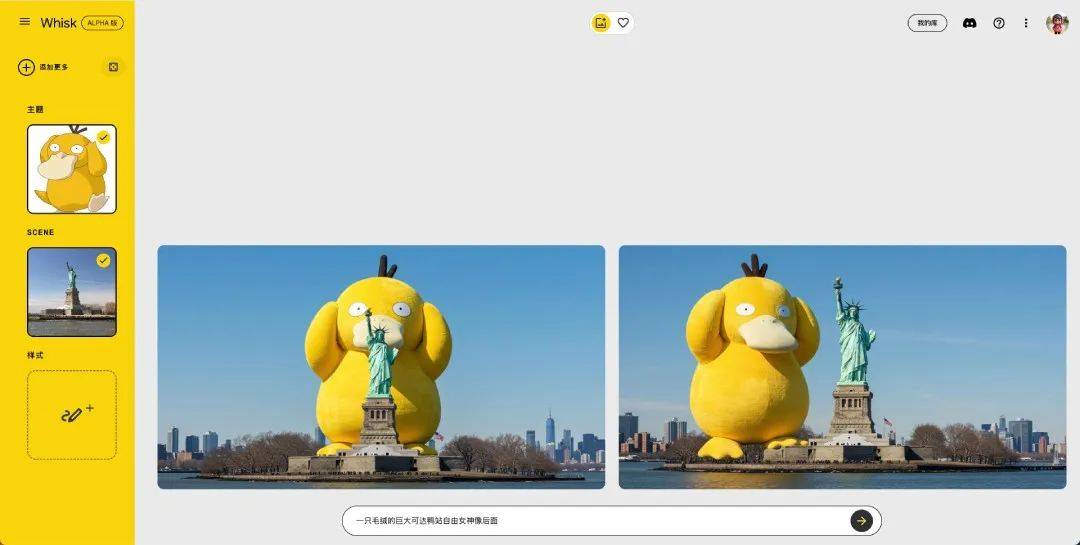
我特别喜欢可达鸭和皮卡丘,先拿它们做巨物宝可梦的视频。
你看,只用 2 张图 + 简单的提示词,效果还行吧?
当然,AI 生图挺像开盲盒,不满意就调整提示词,多生成几次,整体感觉 Whisk 生成效果比别的 AI 生图工具好,也快很多。
生成满意的图片,再用可灵 AI 根据这张图,与提示词描述,生成视频。
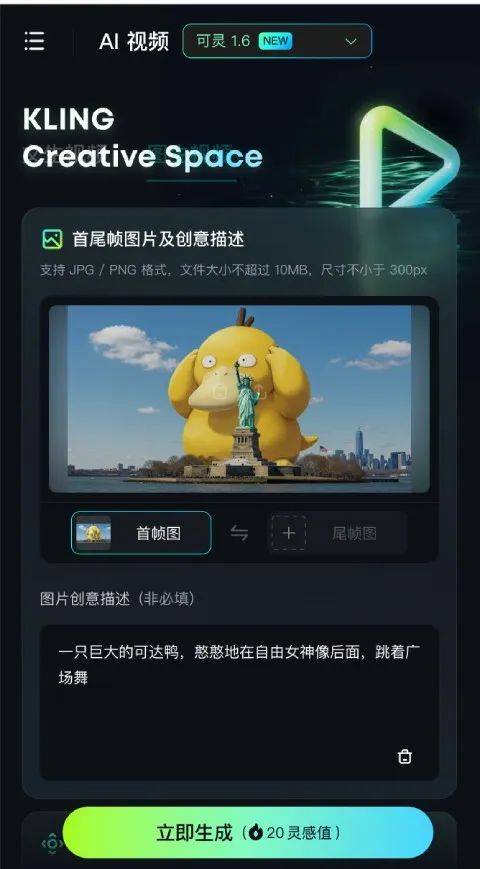
最终成品,看下可达鸭跳舞如何:
再看看皮卡丘在干嘛:
正如 Whisk 的 slogan :prompt Less,Play More(少写提示词,多玩),谷歌做到了。
那 Whisk 怎么实现的呢?
Whisk 为了让我们少写提示词,用 Gemini 模型的多模态能力识别图片,再用谷歌最新的图片生成模型 Imagen 3 生图。
我们上传的图片,会被自动识别并生成详细的描述,然后这些描述会给到 Imagen 3 出图。
也就是说,Whisk 并不是直接拿我们上传的图去融合,而是先转为文本描述提示词。
比如,我上传了一张金字塔的场景,出来的提示词老长了。不得不佩服 Gemini 的多模态识别能力。
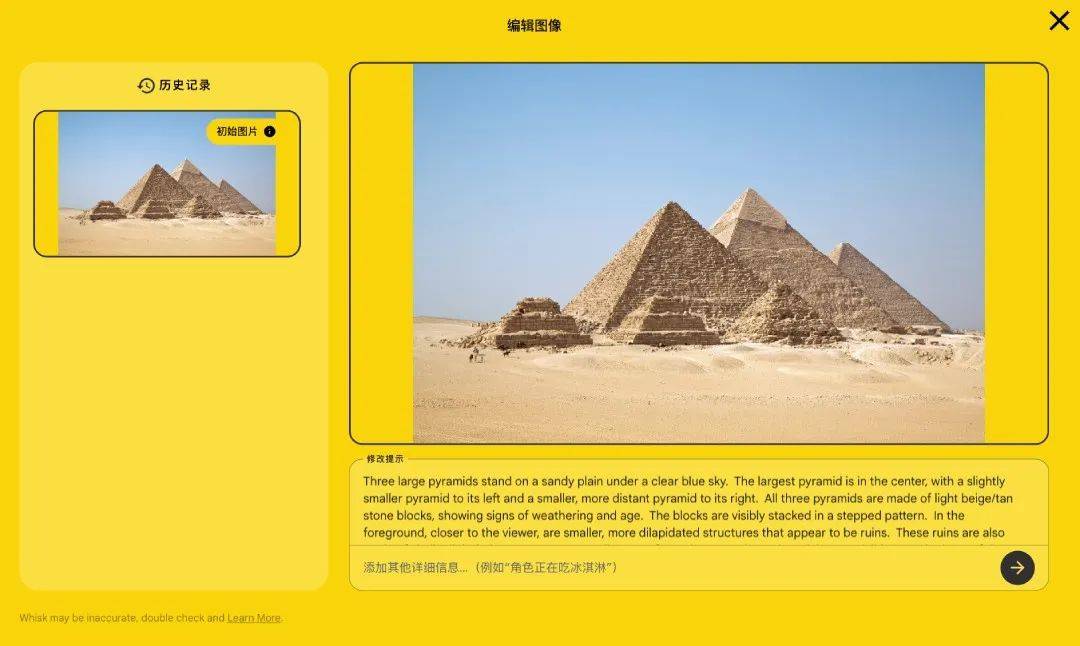
更有意思的是,Whisk 不是精确地复制图片,而是抓住图片的特点,提取关键特征。
这样生成的图片,既能限度保留图片原有特点,又能发散出更多的创意。
生图环节,Whisk 结合「图片转成的描述提示词」 + 「用户写的提示词」,产生一个新的提示词,来生成最终效果图。
点击每张生成的图片,可以看到提示词,也可以自行修改。
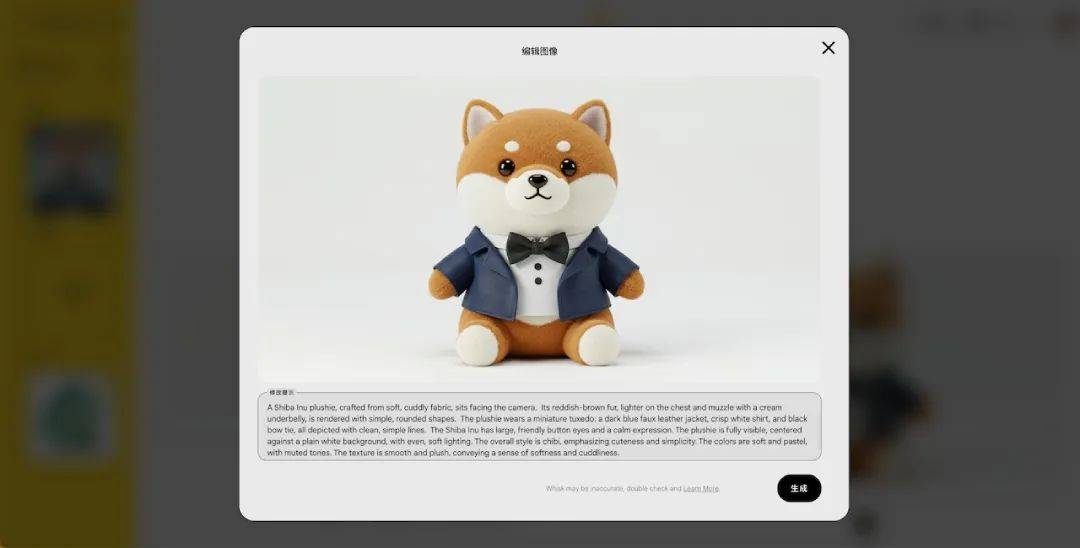
这个转换的过程,用户完全无感知。对用户来说,只需要做 2 步或 3 步操作,但 Whisk 在背后做了大量的处理工作。
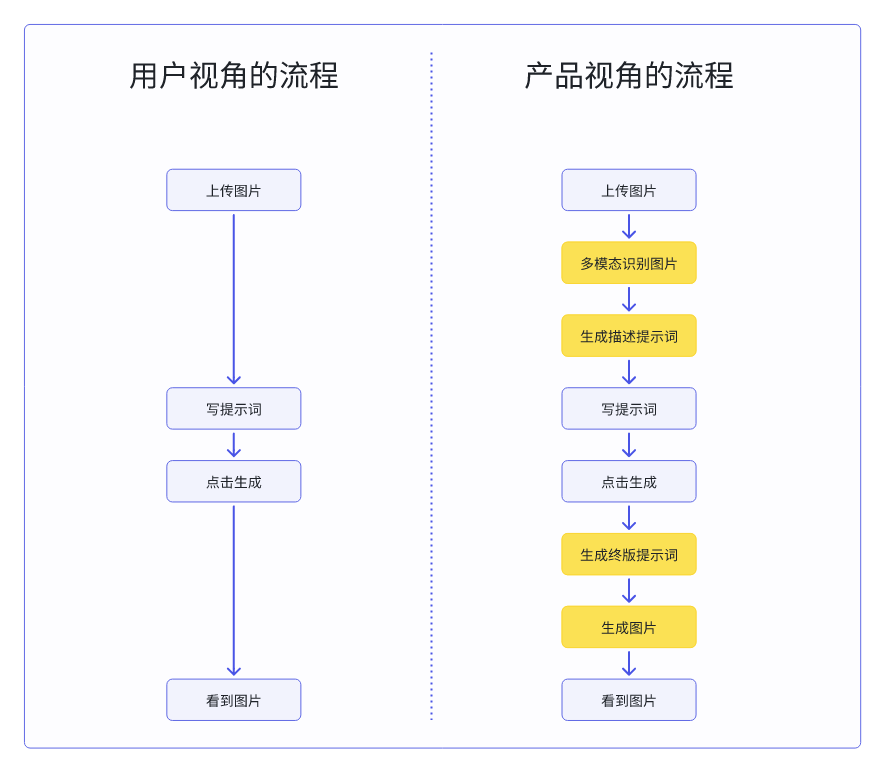
我画个简单流程对比,给你感受下。
Whisk 给产品经理有什么启示?
第一,产品要解决用户核心问题。
Whisk 凭借谷歌自家 Gemini 和 Imagen 3 模型的硬实力,生成图片效果惊艳,能帮用户生成高质量、有创意、好玩的图片,形成核心优势。
第二,Whisk 没有走 AI 生图工具的老路,让用户写复杂的提示词,而是让用户以上传图片为主,去表达想要图片的效果。
要知道,写好提示词,对大多数人来说太难了。反过来,让用户去找图片却容易得多。
我们想做某种图片,往往是看过某些喜欢的图片风格,希望模仿并改成自己的。
这说明 Whisk 把握用户实际的使用场景和痛点非常准。
第三,Whisk 设计一个简化模式,让用户先快速上手,感受生图效果,而不是直接让用户进入完整模式。
用户体验到产品操作简单、效果好,才会继续用。这种方式,降低用户的使用门槛,体验非常好。
做产品,把功能全塞给用户,是满足自己;只给用户所需的功能,才是有用户思维。
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦