仅仅收集和描述数据是远远不够的。
要真正从数据中获取洞见,做出精准的商业判断,你还需要掌握推断统计。
今天,我想和你分享推断统计中最实用的三大武器:假设检验、置信区间和方差分析。
这些工具不仅能帮助你验证直觉,还能让你量化不确定性,甚至比较多个群组之间的差异。
假设检验是推断统计中最基础、也是最常用的工具之一。
简单来说,它就是用数据来检验我们的猜想。
假设你是一家咖啡店的老板:
你觉得换了新的咖啡豆后,顾客更喜欢你的咖啡了
你认为周末延长营业时间会带来更多收入
你怀疑天气会影响饮品的销售种类
这些都是商业直觉,但直觉可能会误导我们。这时候,假设检验就派上用场了!
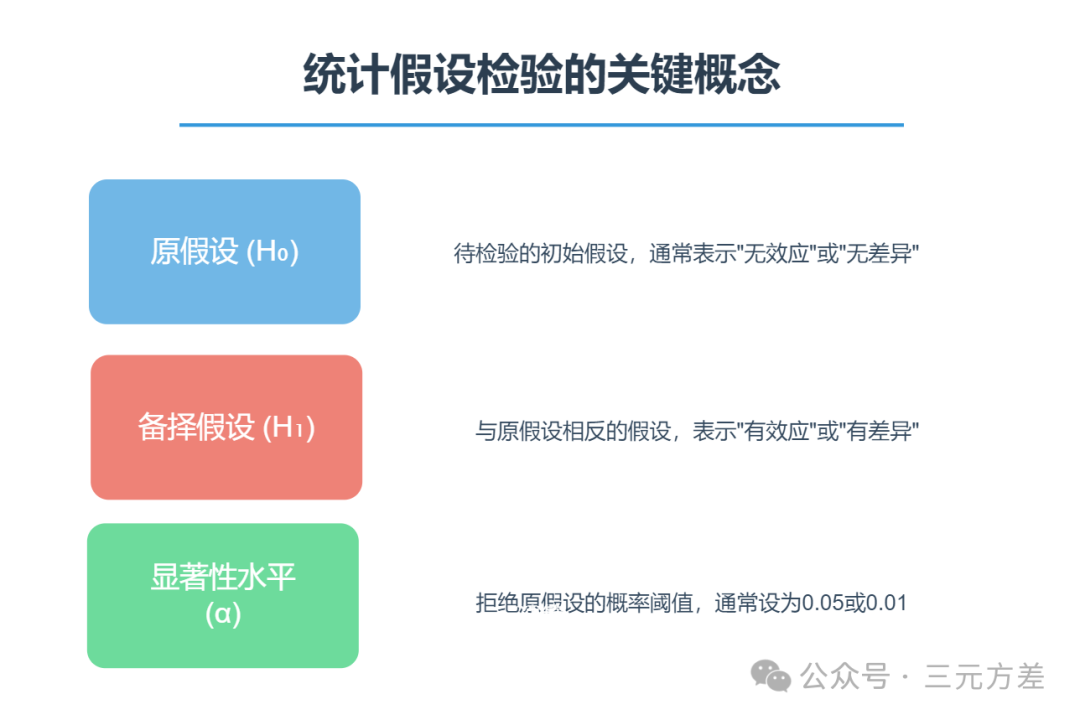
假设检验有几个核心的概念:原假设、备择假设、显著性水平。我们一个个来说:
原假设(H0):这是我们的"无罪推定"
例如:"新咖啡豆和旧咖啡豆对顾客的吸引力没有区别"
备择假设(H1):这是我们真正想证明的
例如:"新咖啡豆更受顾客欢迎"
显著性水平:通常是0.05,就像是证据需要达到的"确信度"
想象在法庭上,我们需要"排除合理怀疑"才能定罪
在数据分析中,我们需要足够的证据才能拒绝原假设
常见的假设检验方法有t检验、Z检验和卡方检验:
t检验:适用于小样本比较均值。
例如,我们可以用配对t检验来比较新功能上线前后100个用户的平均停留时间。如果p值小于0.05,我们就可以说新功能显著增加了用户停留时间。Z检验:适用于大样本比较均值。
假设我们想比较北京和上海用户的平均购买力,样本量有10000+。Z检验就是理想的选择。卡方检验:用于检验分类变量之间的关联。
比如,我们想知道用户的性别是否与他们购买的产品类别有关。卡方检验可以告诉我们这种关联是否显著存在。

虽然p值是假设检验中的重要指标,但我们不能过度依赖它用于业务判断。
记住,p值小于0.05只是告诉我们结果不太可能是偶然发生的,但并不意味着这个结果在实际业务中就一定有意义。
例如,你可能发现一个新的界面设计将转化率从10%提高到了10.1%,p值小于0.05。虽然这个提升在统计上是显著的,但在实际业务中,0.1%的提升可能并不足以证明改版的价值。因为提升幅度实在太小了。
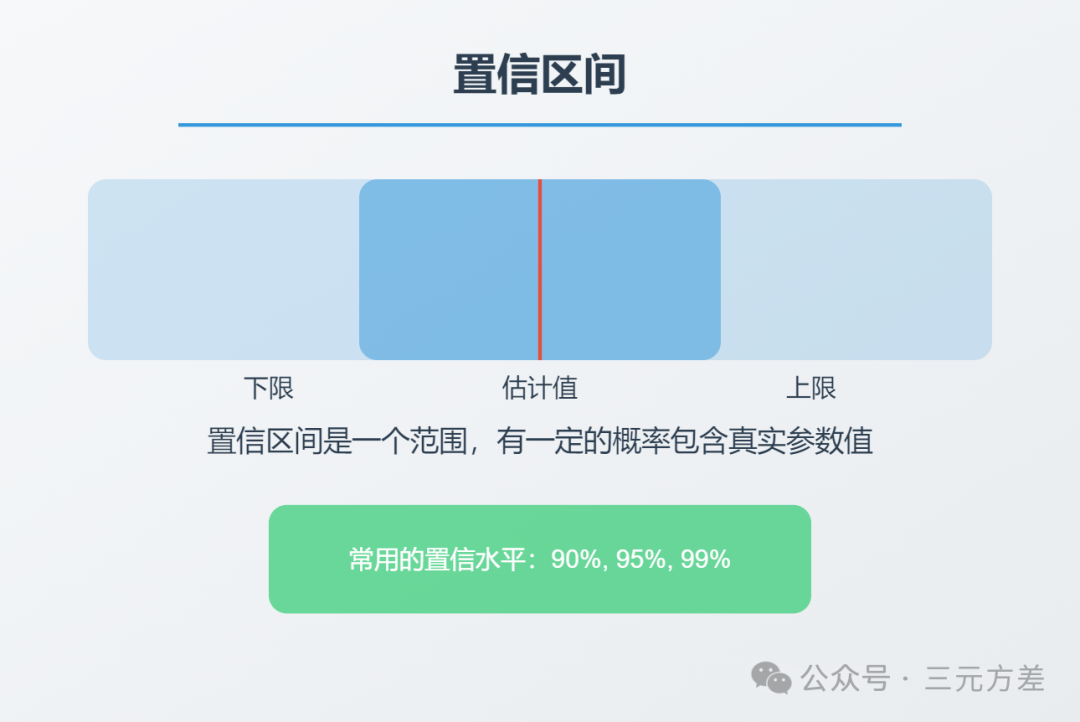
2. 置信区间:量化你的不确定性在商业分析中,我们经常需要做出预测。但是,单一的点估计往往不够用,因为它没有告诉我们预测的可靠程度。这就是置信区间派上用场的时候。
2.1 理解置信区间
想象你需要预测下季度的收入。你可能会说"预计收入为1000万元",但这个预测有多可靠呢?
使用置信区间,你的报告可能会变成:"我们有95%的把握说,下季度收入将在950万到1050万之间。"
95%置信区间的含义是:如果我们重复这个抽样和计算过程很多次,95%的时间,真实值会落在这个区间内。
2.2 置信区间的应用
产品定价策略
假设你要为一个新产品定价。通过市场调研,你得到了一个价格的置信区间:95%置信区间为80-120元。
这意味着你有很大把握说最优价格在这个范围内,给你的定价决策提供了一个合理的参考范围。市场份额估计
在评估广告投放后的品牌认知度变化时,使用置信区间可以让你更准确地描述这个变化。
比如:"我们有90%的把握说,广告投放后,品牌认知度的提升在15%-20%之间。"销售预测
在预测下个季度销量的时候,使用置信区间可以这样表述: 有95%的把握说,下季度销售额将在480万至520万元之间。
这种表述帮助管理层更好地规划库存和资金
记住,置信水平和区间宽度是一个权衡。提高置信水平(如从95%到99%)通常会使区间变宽,而缩小区间宽度则会降低置信水平。
我们需要根据具体情况在精确性和可靠性之间找到平衡
3. 方差分析(ANOVA):多群组比较的利器想象你是一位市场经理,需要比较:
四个不同城市的销售业绩
三种包装设计对销量的影响
五个价格区间的客户满意度
这时,简单的两组比较已经不够用了。方差分析(ANOVA)就是为这种多组比较而生的统计方法。
3.1 ANOVA的基本原理
ANOVA就像是在问:"组与组之间的差异,是否大到不可能是偶然造成的?"
它通过比较两种变异来回答这个问题:
组间变异(不同组的平均值之间的差异)
组内变异(每个组内部的数据波动)
为什么不直接做多次t检验呢?
因为多次使用t检验会增加犯第一类错误(误认为有显著差异)的概率。ANOVA通过一次性比较所有组,避免了这个问题。
设想你要比较4个产品的性能:
需要进行6次两两比较(甲和乙、甲和丙、甲和丁、乙和丙、乙和丁、丙和丁)
每次比较都有5%的几率犯错(假设显著性水平为0.05)
多次比较会大大增加总的错误概率
ANOVA通过一次性比较所有组,优雅地解决了这个问题。
3.2 单因素ANOVA vs 多因素ANOVA
单因素ANOVA 适用于比较一个变量的影响。
例如,比较不同营销渠道(如微信、微博、抖音)的获客成本。如果ANOVA的结果显示p<0.05,我们就可以说不同渠道的获客成本存在显著差异。多因素ANOVA 考虑多个变量的交互作用。
比如,我们想同时考虑广告投放时间(早上、下午、晚上)和平台(PC、移动)对点击率的影响。多因素ANOVA不仅能告诉我们时间和平台各自的影响,还能揭示它们之间可能存在的交互作用。
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦