作者|Cindy
恐怕谁也不会想到,百模大战进入商业化下半场,围绕大模型大规模、旷日持久的战争,竟是开源和闭源路线的交锋。
最近,在2024世界人工智能大会(WAIC)上,刘庆峰、李彦宏、王坚、朱啸虎、傅盛等行业大佬,发表的截然不同观点,再次引发外界对大模型路线的关注。
比如,持续输出开源落后于闭源大模型场景下,开源是最贵的观点的百度创始人李彦宏,再次直言不讳认为,开源是一种智商税。猎豹移动董事长兼CEO傅盛,则继王小川、周鸿祎之后,直接不客气反驳李彦宏,称付费闭源大模型才是智商税。谷歌前董事长施密特甚至在近日表示,中国AI发展基本靠西方开源,因此必须限制开源模型。
大模型赛道的开源闭源,主要是指模型源代码、模型权重、训练数据是否公开。这场AI浪潮下科学界的战争,并非仅发生在中国企业身上——相比中国企业家的文明交锋,国外企业和大佬更是采用直接短兵相接的肉搏战方式。
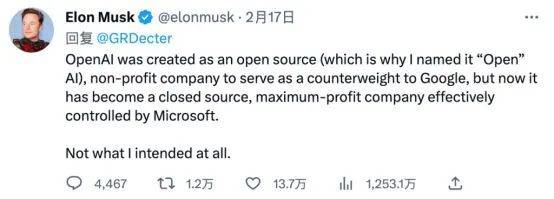
去年2月以来,马斯克屡屡发难,称转向闭源的OpenAI应改名为Close AI。今年2月,马斯克在旧金山法院对OpenAI及CEO阿尔特提起诉讼,要求OpenAI恢复开源并给予赔偿。市场方面,去年7月meta将Llama2(羊驼)开源后,和ChatGPT发生的一轮轮攻防战,同样精彩纷呈。
风云涌动中,围绕大模型开闭源的白刃战超过一年半。但至今谁也说服不了谁,谁也未取得决定性胜利,未来走向扑朔迷离。
唯一能确定的是,对公众和企业来说,无论路线如何,解决不了最后一公里难题,开闭源都一文不值。对所有大模型而言,其真正考验如同科大讯飞创始人刘庆峰所说,在最后一公里的应用和商业化落地上。
01、开闭源路线之争的本质
回顾互联网和软件史,开源和闭源的战争一直都在上演。
直到今天,这依然是两股并行、截然不同的力量。开源方面,以Linux、Android、unix为代表;闭源方面,则有Windows、Mac OS、iOS、WP等等。

战争核心,在于技术进步、安全保障、社会价值与经济效益之间的平衡探索。
开源认为,应允许任何人获得并修改软件的源代码,如同一座桥梁,分享、融合才是其存在意义。闭源则认为,软件和代码属于劳动成果,劳动成果需要保护和用来获取财富。
客观看,开源促进软件繁荣和全球范围内合作,拓宽创新边界上,居功至伟。但就商业价值层面来看,此前所有领域都被闭源吊打。
一切技术路线争议终点,需要商业化挣钱。这无可厚非,但需要意识到的是,AI大模型的路线战争,和此前任何一次开闭源战争都没可对比性——业界共识是,大模型本身就是一个黑盒子,外界至今难以彻底揭开它的神秘。
从模型、算法到数据,如何产生一个可以使用的模型,无人知晓。未来到底是走向中心化,还是去中心化,都是矛盾而又流行的说法。
这种神秘性,造就大模型的独特性——无论是国外还是国内,都不是巨头的一枝独秀,从科研到创业者,再到千行百业开发者,都可以参与其中,让大模型呈现百花齐放、百家争鸣的蓬勃生态。
技术实力来看,如果以ChatGPT为标尺,那么开源曾很长一段时间落后于闭源——到去年下半年,这种情况已经改变,很多超过 ChatGPT 3.5,甚至追赶ChatGPT 4.0能力的大模型陆续发布。不过,在Sora发布后,闭源又获得一段时间领先。

闭源和开源大模型,很难说谁就会永远领先谁,这是一个永远在动态平衡变化的状态。多位业内人士就认为,其差距取决于,研发团队能力的差异,以及背后团队所持有的资金、算力、数据。
非得在开源与闭源之间,做选择题吗?显然不是。
如今,在开闭源阵营之争外,还有一条技术路线阵营正迅速扩大——开源和闭源同时并行发展。在国外,以谷歌为代表;在国内,则包含科大讯飞、昆仑万维、零一万物、百川智能等企业。
这个阵营的技术实力,并不逊色任何开源或闭源企业。比如讯飞星火,V3.0版本在中文上全方位超越Chat GPT,英文上实现对标。而在V4.0版本中,在8个国际主流测试集中排名第一,在文本生成、语言理解、知识问答、逻辑推理、数学能力等方面实现了对GPT-4 Turbo的整体超越。
02、开源与闭源,为何可以两条腿走路
极点商业观察来看,选择开源、闭源两条腿走路的企业,布局大多主要遵循以下路径:在最大模型上选择闭源,在较小模型上选择开源。
比如谷歌,就在推出开源大模型Gemma后,走上闭源+开源并行道路。有报道认为这代表谷歌大模型策略的转变——开源主打性能最强大的小规模模型,希望战胜meta和Mistral AI;闭源则主打规模大效果最好的大模型,希望尽快追上OpenAI。
在国内,两条腿走路的企业也类似。以科大讯飞为例,整体超越GPT-4 Turbo的讯飞星火V4.0是闭源,通过昇腾AI和讯飞星火的合作,打破大模型训练的瓶颈;而130亿参数的星火开源-13B则是开源,在多项知名公开评测任务中名列前茅。
其实,大模型不像手机操作系统,必须在IOS或安卓之间二选一,对开发者、用户、企业来说,考虑的很直接:这个大模型是否易用好用,又同时具有性价比?稳定性、安全性是否可以保证?其生态和场景打造,又是否满足用户需求。
这意味着,让所有用户、企业、开发者乃至产业,都能选择合适自己的大模型,就是最好的大模型。
这也是科大讯飞两条腿走路核心目的,通过闭源+开源完整体系,闭源专注商业应用、产业落地,开源策略是生态开放,两者优势合二为一,激发中国大模型的产业、生态活力。
在闭源部分,基于星火大模型V4.0,科大讯飞有面向TOC的AI应用讯飞星火APP/Desk、星火智能批阅机、讯飞AI学习机、讯飞晓医APP;面向TOB和生态伙伴,有星火企业智能体平台、招采助手、机器人超脑平台2. 0等等,让企业可以构建自己的智算底座。
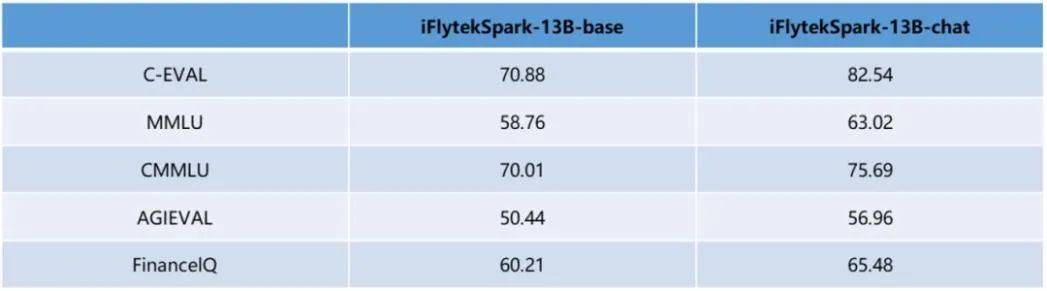
星火开源公开测评数据
在开源的星火大模型,科大讯飞的策略是生态开放,通过免费大模型,为开发者、学术界赋能。
开源+闭源两条腿想顺利走路关键,需要解决几个关键问题,一是模型架构自主可控,有一定技术优势,二是产业落地、商业模式完整,三是通过社区吸引更多开发者。
谁控制了过去,谁就控制了未来;谁控制了现在,谁就控制了过去。近年来,被卡脖子事件屡屡在我国科技产业上演,算力、数据是否会卡大模型的脖子,业界也是议论纷纷。
这意味着,主流国产、自主可控的模型架构,才可能最大限度发挥生态力量,匹配产业上下游环境,更好推进开源、闭源的并行融合。
所有算法都是我们自主可控的,大模型的每一行代码、每一个数据都是我们自己编写、清洗出来的。刘庆峰表示。
而对处于早期的大模型来说,无论是开源、闭源,都需要聚集更多开发者,参与到开源模型的改进和优化。
在国外,包括meta、谷歌和微软以及第三方开发者都在社区内发布模型、参数、数据集;在国内,讯飞开放平台之上大模型总开发者超35万,其中企业开发者超22万,推动大模型应用加速落地。
回顾PC、软件、手机历史,其实也有类似案例。比如在数据库市场,Oracle就是开源+闭源两条腿走路,在开源社区、商业应用均取得了巨大成功。
谷歌、科大讯飞们的大模型两条路逻辑其实也类似。一种解读是,在大模型时代,开源、闭源只是手段,在不同产品和应用场景中,两者本是相辅相成。开源模型和开源社区可以在上游用免费策略负责扩大用户基数、拓展产业生态、迭代模型技术。
来自开源部分的经验,也可以复用到闭源,让闭源大模型的产业化、商业化落地更顺畅——最终两条路线以多元化、灵活化的方式演进,并行甚至融合互补。
实际上这两块是相互补充的。科大讯飞创始人刘庆峰也认为。他以星火开源13B模型为例指出,等650亿、1500亿、1750亿参数以及更大模型出来,就知道了它的天花板和边界,再对它进行裁剪、浓缩,就变成13B,那13B的效果也提升了。
如果不做闭源,不探索行业最高的天花板,开源也做不到最好。刘庆峰就认为。
两条腿走路的互补价值,浙江大学人工智能研究所所长吴飞一个观点是,任何开源基座模型,都是千锤百炼而来,不是所有公司和机构都具备这样的能力。在开源之上进行闭源,可以很大程度上降低闭源模型研发的门槛。
03、最后一公里才是真正挑战
从刘庆峰、李彦宏、王小川等行业大佬观点来看,一个共同之处是:闭源、开源只是手段,关键是让大模型,如何快速应用千行百业场景里,如何作为生产力工具,更好地普惠,去替代人类完成各类业务流的碎片、繁杂工作。
这意味着,对国内目前尚处于高速发展阶段的大模型而言,随着开源、闭源路线的逐渐并行融合,选择什么路线不是关键问题。
不同场景适配不同的参数。如同刘庆峰所说,无论大模型如何演进,最后一公里的产品体验和应用落地,才是真正挑战。
这也是谁能在百模大战中占有一席之地,拥有更多的话语权的关键。如果解决不好最后一公里,那么技术路线将一文不值。当前国内大模型企业的应用开发的普遍思路是,并未等到技术完全成熟再落地应用,而是在快速迭代技术同时,从ToC、ToB两端入手,相应地进行产业和应用落地。
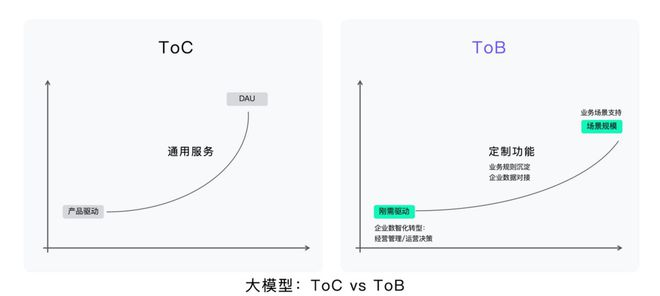
这一点,在刚刚结束的WAIC上也体现得很明显。科大讯飞、百度、阿里巴巴、腾讯、华为、字节跳动、快手等行业巨头,以及百川、智谱等新锐带来众多新技术和新产品,展现了大模型和金融、医疗、教育、政务等多个行业、产业的深度融合。
关于如何更好地解决企业大模型应用的最后一公里问题,科大讯飞经过和大量的央国企和行业合作伙伴的共同探讨,他们认为用智能体平台打造每个岗位专属助手的时间已经到了。
在这之前,星火已经成功赋能了很多场景,无论是代码、数字劳动力,还是评标、客户、APP智能互动。科大讯飞与太平洋保险合作是从审计这个岗位做起的,包括客服和评标;此外,国家能源集团、中国石油等公司选了科大讯飞作为合作伙伴;同时,星火大模型赋能中国移动APP几亿用户,使中国移动APP更加智能、交互更顺畅。
通过这么多的场景可以看到,大模型赋能企业人工智能+行动有两个方面:一方面是大模型直接完成任务,讯飞星火一开始启用,文本生成、语言理解、知识问答、逻辑推理和代码能力对应到下面相关的各种各样的工具,它自己就完成了,不需要借助任何外力。
还有一种模式是以认知大模型为中心大脑,它调动各种专用模型,比如说振动的模型、味觉模型、气体模型,湿度模型等各种模型,然后配合相应的工具,再对接内外部的各种信源和数据,打通内部的办公OA、ERP系统,再对接外部实时性来联合完成任务,相当于用大模型来指挥调度一系列的能力,从而完成一个综合的任务。

面向B端,从刘庆峰阐述来看,讯飞星火大模型在最后一公里用智能体平台打造专属于每个岗位的工作助手,在智能家电、智能汽车、运营商、机器人等行业场景实现全面赋能,甚至成为各行各业创新发展的重要驱动力。
面向具身智能和人形机器人企业需求,目前400+机器人企业已经采用讯飞机器人超脑平台。另外,星火企业智能体平台将围绕智能体关键能力,覆盖400+AI原子能力,集成 90+外部信源,打通100+内部 IT 系统,可供企业结合业务场景快速构建可落地的智能体应用。
解决AI+行动的最后一公里的问题,是前所未有的机遇。刘庆峰就表示,星火已经成功赋能了很多场景,无论是代码、数字劳动力,还是评标、客户、APP智能互动。
不完全统计显示,讯飞星火大模型正成为国家能源集团、中国石油、中国移动、中国人保、太平洋保险、交通银行、海尔集团、美的集团等多领域头部企业的首选。
公开招标网数据就显示,今年上半年到6月中旬,整个公开招标数量约为234件。其中,60%以上的项目来自央国企。在央国企大模型订单中标企业中,讯飞星火高居第一。
我们能走多远,取决于我们是否拥有自主开发的、可控的基础能。从刘庆峰表态来看,这是大模型如何解放生产力、释放每个人、每家企业,甚至每位开发者想象力的关键。
合抱之木,生于毫末,九层之台,起于垒土。如同刘庆峰的说法,这正是大模型能力阶段跨越的体现——意味着大模型从技术附加工具,转向引领行业变革、助力企业降本增效、普惠大众生活的关键阶段。而针对更多商业化模式的探索,也正悄然形成模型越强、落地越多、用户越广、算力越大的增长飞轮。
从这个角度看,只要能做大生态,加速产业最后一公里的落地,无论是大模型技术路线是闭源,还是开源,其实一点都不重要。
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦