大家好,我是策略产品夏师傅。
产品经理无论在进行日常的数据分析,还是AB实验数据整理,我们都会看到一些不合群的数据,也就是看上去就觉得有问题的数据。
那么当我们遇到这种数据,该如何处理?
一般来说包含两步:
1. 确定是否异常
2. 处理异常数据
接下来我们分别看一下每一步该如何操作。
01 确定异常数据
确定异常数据是指我们如何从大量的数据当中定位出那些不太合理的数据。一般我们可以用下面的几种方法:
第一种就是先验知识输入。通常我们对于某个具体的数据指标都会有一个先验的知识,比如对于ctr,正常的统计口径下,他一定是一个[0%,100%]的数据,所以如果你对某个区域的ctr进行分析,那么所分析的数据也应该是处于[0%,100%]这个范围。
第二种就是3倍标准差方法。这种方法有一个前提,就是数据整体的分布呈现正态分布。那么这个方法怎么用,原理如下:
在统计学当中,通常把等于 ±3σ的误差作为极限误差,对于正态分布的数据来说,落在 ±3σ以外的概率只有 0.27%,所以正是这种概率事件让我们认为如果超过3倍的标准差,那么基本可以确定为是异常的。
怎么比较?
测量值-平均值的绝对值大于3倍的标准差,那么即认为这个数值是异常值
第三种是excel当中常的一种数据图形类型,箱型图,比较类似股票的蜡烛线。
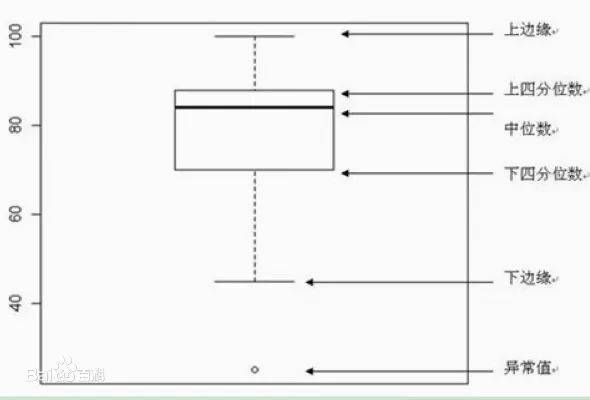
根据箱型图的作图方法进行绘制,如果发现测量值位于了上下边缘的外边,那么即为异常值。
02 如何处理异常值
异常值的处理有很多种方法,今天跟大家讲几种比较常见的方法:
1. 删除。最常见,简单的方法无非就针对异常值进行删除处理,一般比比较适用于样本量比较足的情况,比如你做AB数据,总共收集了7天的指标数据,那么就不太适合用这种方法处理。
2. 修正。所谓的修正是指我们利用某个一个比较折中的值去进行修改。比如你可以用两个观测值的平均数来进行修正,这种方法比较适合样本量较小的时候使用,效果还不错。
其实,上面两种处理办法对于产品经理进行基础的数据分析基本能够满足了。
3. 分箱法。直接采用百度百科的概念,它是指过考察邻居(周围的值)来平滑存储数据的值,用箱的深度表示不同的箱里有相同个数的数据,用箱的宽度来表示每个箱值的取值区间。
举例:
假设有8、24、15、41、6、10、18、67、25等9个数,先对数进行从小到大的排序,6、8、10、15、18、24、25、41、67,再分为3箱。
箱1:6、8、10
箱2:15、18、24
箱3:25、41、67
分别用三种不同的分箱法求出平滑存储数据的值:
按箱平均值求得平滑数据值:箱1:8,8,8,平均值是8,这样该箱中的每一个值被替换为8。
按箱中值求得平滑数据值:箱2:18,18,18 ,可以使用按箱中值平滑,此时,箱中的每一个值被箱中的中值替换。
按箱边界值求得平滑数据值:箱3:25,25,67,箱中的最大和最小值被视为箱边界。箱中的每一个值都被最近的边界值替换。
通过不同分箱方法求解的平滑数据值,就是同一箱中3个数的存储数据的值。
4. 不处理。采用这种方法是有条件的,实际并不是不处理,只不过会把这个处理的过程给滞后了。所以对后续的环境要求较高,通常是后续环节采用了一些相对数据异常,缺失不敏感的模型。
以上4种是在做数据分析时常见的一些异常值处理手段。
当然,还有很多其他的方式,比如缺失、插补的思路一般来说在模型的数据预处理阶段使用较多,产品经理做日常数据分析时候所用较少,所以了解即可。
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦