图片来源:摄图网
随着人工智能技术的深入发展,大模型成为各企业竞相追逐的热门赛道。大模型在语音识别、自然语言处理、图像识别等领域展现出巨大潜力,各大科技巨头纷纷加大投入,竞相研发更强大的大模型,以提升人工智能系统的性能和智能化水平。
当地时间4月18日,meta在官网上宣布公布了旗下最新开源大模型Llama 3。目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本。根据meta官方介绍,Llama 3在两个定制的24K GPU集群上基于超过15T的数据进行了训练——这比Llama 2使用的数据集大7倍,多4倍的代码,并且Llama 3支持8K上下文长度,是Llama 2容量的两倍。
未来,meta将推出Llama 3的更大参数版本,其将拥有超过4000亿参数。业界指出,这是目前为止最先进的开源模型,将对包括OpenAI在内的大模型公司形成强力竞争。
对于meta推出最新开源大模型,业界对开源大模型看法不一。百度CEO李彦宏曾公开表示,开源模型会越来越落后。他认为,大家以前用开源觉得开源便宜,其实在大模型场景下,开源是最贵的。所以开源模型会越来越落后。
而360集团的创始人周鸿祎却表达了不同看法。周鸿祎表示,自己一直相信开源的力量,至于说网上有些名人胡说八道,你们别被忽悠了。他说开源不如闭源好?连说这话的公司自己都是借助了开源的力量才成长到今天。周鸿祎认为,开源是科技发展的重要推动力。没有开源就没有Linux,而没有Linux就没有今天的互联网。他鼓励企业和开发者们充分利用开源资源,共同推动科技进步。
从meta推出最新开源大模型回看AIGC行业发展情况:
——AI大模型是一种新的智能计算范式
AIGC全称为AI-Geneated Content,指基于大型预训练模型、生成对抗网络GAN等人工智能技术,通过已有数据寻找规律,并通过适当的泛化能力生成相关内容的技术。
超大规模智能模型,简称大模型,是近年兴起的一种新的人工智能计算范式。和传统AI模型相比,大模型的训练使用了更多的数据,具有更好的泛化性,可以应用到更广泛的下游任务中。按照应用场景划分,AI大模型主要包括语言大模型、视觉大模型和多模态大模型等。业界典型的自然语言大模型有GPT-3、源、悟道和文心等。视觉大模型也已广泛应用于自动驾驶、智能安防、医学影像等领域。基于多模态大模型的以文生图技术也迅速发展,AI内容生成(AI Generated Content,AIGC)已成为下一个AI发展的重点领域。

——预训练大模型成为人工智能领导者的竞争焦点
预训练大模型是人工智能产业发展的必然选择,基于海量行业数据和知识,通过强大算力集群,预先训练基础模型,并结合应用场景的数据和各类需求,通过预训练大模型+任务微调的方式,进行工业化的高效率开发。开发者利用预训练大模型,只需要少量数据,就可以快速开发出精度更高、泛化能力更强的行业模型。预训练大模型可以提升人工智能项目开发效率,降低研发成本,缩短研发时间,解决人工智能项目碎片化的问题。
根据Omdia的数据,中国开发者对基于昇思MindSpore打造的盘古NLP大模型最感兴趣。首先,盘古NLP大模型在技术上处于领先地位,千亿参数模型,学习了40TB的中文文本数据,在中文领域有天生优势;其次,盘古NLP大模型可覆盖多个场景下语言处理的任务和需求,泛化能力强,在知识问答、知识检索、知识推理等文本生成领域有广泛应用前景;另外,盘古NLP大模型对开发者友好,可以让开发者能用拖拉拽的方式使用大模型,开发和生产成本低。这也从另外一个角度验证了盘古大模型的开放性,开发者可以跨平台快速调用盘古大模型,与其他工具和应用结合使用。

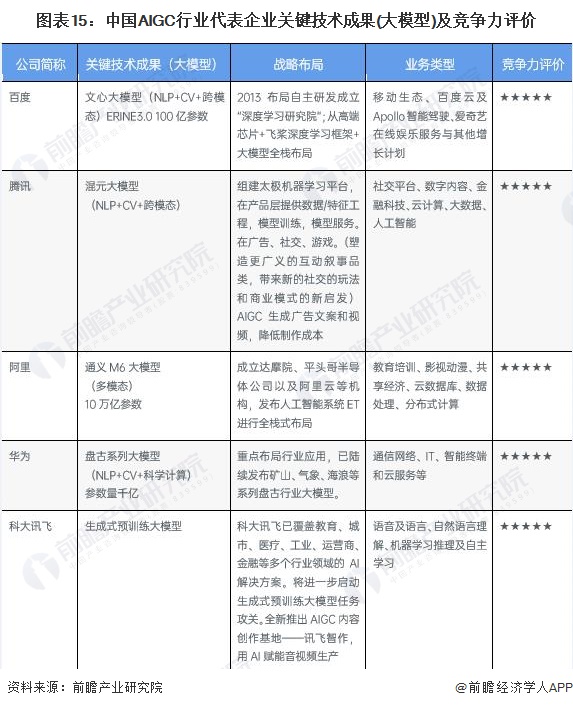
——AIGC行业主要企业关键技术成果(大模型)及竞争力评价
中国AIGC行业的头部代表性企业中,目前互联网大厂的业务布局最广,主要分布在一线城市和新一线城市,且纷纷在各赛道进行宏观战略布局。但其他初创企业也有自身的优势,在细分赛道也有一番成绩。目前国内已经出现了多家从事大模型开发及延展应用的公司,目前尚未普遍形成对外开放的生态,需要进一步关注相关机构的后续动态。
产业研究院分析认为,2023-2025年是我国AIGC产业市场规模增长的第一阶段,增长率维持在25%左右,2025年市场规模达到约260亿人民币。2025年开始,由于行业生态完善(特别是底层大模型完成对外开放),应用层蓬勃将带动产业快速增长,年复合增长率将超过70%。预计2027年我国AIGC产业规模超600亿人民币,2028年开始,AIGC产业将延展出完整产业链,并在商业化场景上持续拓宽加深,深入变革行业。2028年起,我国AIGC产业规模将持续保高速增长,2030年市场规模超万亿。
经济学人APP资讯组
看完觉得写得好的,不防打赏一元,以支持蓝海情报网揭秘更多好的项目。

感谢您的支持,我会继续努力的!



打开支付宝扫一扫,即可进行扫码打赏哦
手机直接保存图片,扫一扫识别二维码,即可进行扫码打赏哦